这是2018CVPR的一篇论文,旨在说明使用深度学习的方法使得暗光条件下的图像更明显。一般来说低光照条件下的图像噪点更多,使用一些方法增强图像或是引入更多的噪点,或是由于曝光时间过长导致抖动产生图像上的模糊。而目前增强暗光图像的方法还不试用于非常暗光和非常短曝光时间的图像,所以文章认为可以充分利用raw类型的数据进行图像增强。如下图所示,一般增强后的图像中噪点非常多:

论文首先是制作数据集,使用长曝光(100-300倍曝光时间于原图像)的方式获得目标图像。并使用方法避免抖动,同时图像数据也包括室内和室外数据,主要通过两种相机获得使得输入图像数据排列有两种形式。
在网络处理数据时,这里是使用看FCN结构。输入数据时,bayer数据被分为四个通道,并进行两倍的下采样(如下图)。对于X-trans类型的图像数据,数据被安排成6x6的块,可以通过交换相邻元素的方法将其分到九个通道里(下图没有显示)。然后减去图像的黑色像素并按照一定尺度对图像像素进行缩放,最后网络输出是12通道只有一半分辨率的图像数据,通过一个sub-pixel层可以恢复到原来的分辨率。
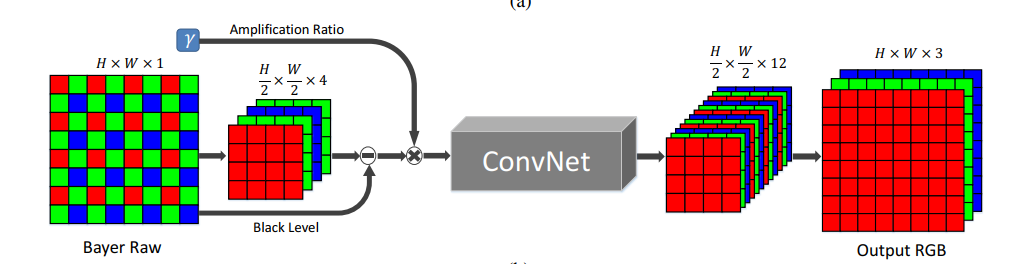
网络使用可快速处理图像的CAN或U-net作为核心架构,由于需要处理全分辨率的图像,所以不使用全连接的结构,默认使用的基本架构是U-net。此外,上图中的放大系数在测试时可以通过用户的设定来决定图像的输出亮度。输出的图像是在RGB空间的,调整不同放大系数的结果如下图所示。

我们使用 L1 损失和 Adam 优化器,从零开始训练我们的网络。在训练期间,网络输入是原始的短曝光图像,在 sRGB 空间中的真实数据是相应的长曝光时间图像(由一个原始图像处理库 libraw 处理过得参考图像)。我们为每台相机训练一个网络,并将原始图像和参考图像之间曝光时间的倍数差作为我们的放大因子(例如,x100,x250,或x300)。在每次训练迭代中,我们随机裁剪一个512×512的补丁用于训练并利用翻转、旋转等操作来随机增强数据。初始学习率设定为0.0001,在2000次迭代后学习率降为0.00001,训练一共进行4000次迭代。
最终的实验结果要比传统的增强算法/传统增强算法加上去噪都要好,同时在测试其他手机获取的图像也有较好的效果。如下图所示:


主观问卷调查也是我们的方法效果更好:

此外,论文还做了一些对比组实验,主要是从PSNR和SSIM指标上进行对比,对比结果如下表所示:

简而言之就是,U-net在PSNR上要比CAN要好,SSIM上比CAN略差,但是CAN处理后的图像容易出现色彩失真;raw数据的效果要比rgb数据的效果要好;L1损失,L2损失和SSIM损失效果相近,但是加上GAN的感知损失准确率会明显下降;此外,还通过对比说明我们的数据组织形式也是合理的;最后,将目标图像做直方图均衡化后再作为目标图像的效果没有直接用目标图像的效果好,虽然更亮但是不够清晰,可以用原来目标图像训练出的结果再直方图均衡化。
当然,整个过程还有很多不足,包括:数据集种类不是很足,缺少人物和动图;放大系数需要手动调节;只针对特定相机,泛化性能不是很好;对图像处理的速度不足够快等。