VESPCN
比较早的一个做视频超分的论文,是在ESPCN基础上做出的改进,将动作补偿和视频超分辨联合起来进行端到端的训练。对于视频超分辨来说,同一个场景不同帧之间的信息之间存在冗余,这个是可以限制求解空间的。视频超分问题的一个先验是,同一场景的视频图像可以被单幅图像和运动模式所近似。因此该论文借鉴了STN里推断两个图像的映射参数,将其用在视频运动补偿里,实现视频超分,整体框架如下所示:

上采样采用的是subpixel shuffle的形式,这里就不说了。Spatio-temporal网络采用的是3D conv,其是slow fusion的一种权重共享形式,如下所示:

spatial transformer motion compensation网络如下所示,先估计一个粗糙的光流得到粗糙的目标帧,然后这两个再和原始的两个帧输入网络得到精细的光流。最后将精细的光流和粗糙的光流对原始的两帧进行warp得到最后的帧,输出使用tanh激活函数。warp过程就是用STN实现的。为了训练这个网络,作者设置了MSE损失和Huber loss两种损失。
实验发现多帧效果比单帧要好,但是帧数太多也会导致性能下降。
参考:
https://blog.csdn.net/u014447845/article/details/89928794
Detail-revealing Deep Video Super-resolution
视频超分辨主要关注:1.如何充分利用多帧关联信息;2.如何有效融合图像细节到高分辨率图像中。论文提出SPMC,用来进行有效的动作补偿和特征图缩放,同时使用LSTM处理多帧输入。整体框图如下所示:
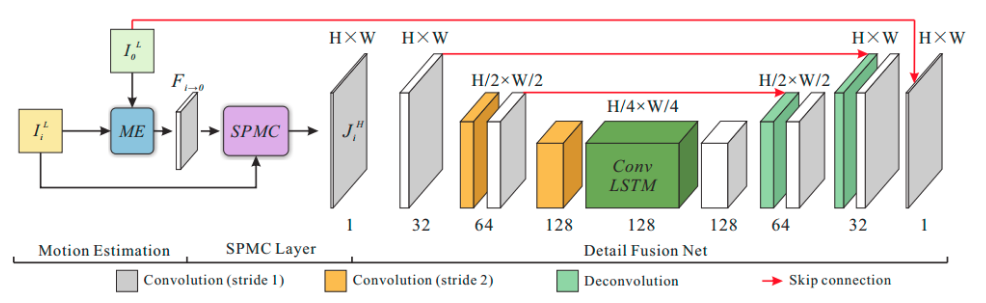
ME就是motion estimation,这里作者使用运动补偿转换MCT去实现,获得运动补偿估计F。
然后是运动补偿模块SPMC,这里令LR和HR图像分别是$J^L$和$J^H$,后者通过前者结合光流F得到,公式比较复杂,这里懒得写了。
下面获得的$J^H$是比较稀疏的,这里设计一个encoder-decoder结构,使得特征图不稀疏,多帧图片进入LSTM模块,处理帧内关键信息,然后再反卷积。
训练时分别训练,先训练ME的部分,再固定前面训练后面ST的部分,最后联合训练。
参考:
https://blog.csdn.net/Cyiano/article/details/78368271
Fast Spatio-Temporal Residual Network for Video Super-Resolution
19年的CVPR,如果直接使用运动补偿,会有巨大的计算量且要人为设计结构。如果要自动计算时空信息,就会使用三维卷积,但是会引入大量参数,导致深度不够,效果不好。这篇论文使用p3d进行改进,整体结构如下:
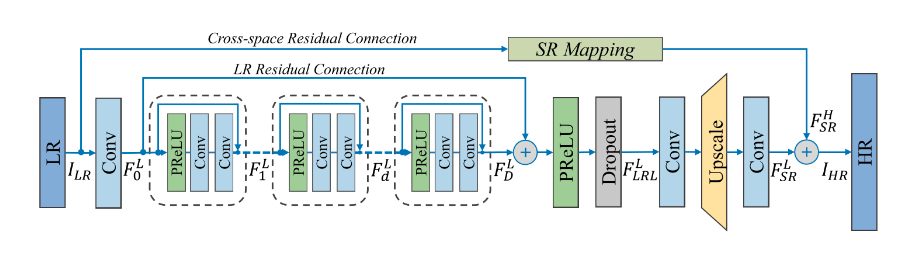
整体包括,低分辨率特征提取LFENet,快速时空残差模块(FRBs),低分辨率特征融合和上采样超分辨网络(LSRNet),全局残差学习(GRL)。。第四部分由低分辨率空间残差学习(LRL)和交叉空间残差学习(CRL)组成(最上面的那个部分)。
LFENet:使用一个C3D层对初始的输入低分辨图像做一个特征提取,交给后面的FRBs处理。
FRBs:对前面那个LFENet输出做进一步处理,堆叠多个网络,里面有残差连接。
LSRNet:就是对上采样后的图像的一个融合
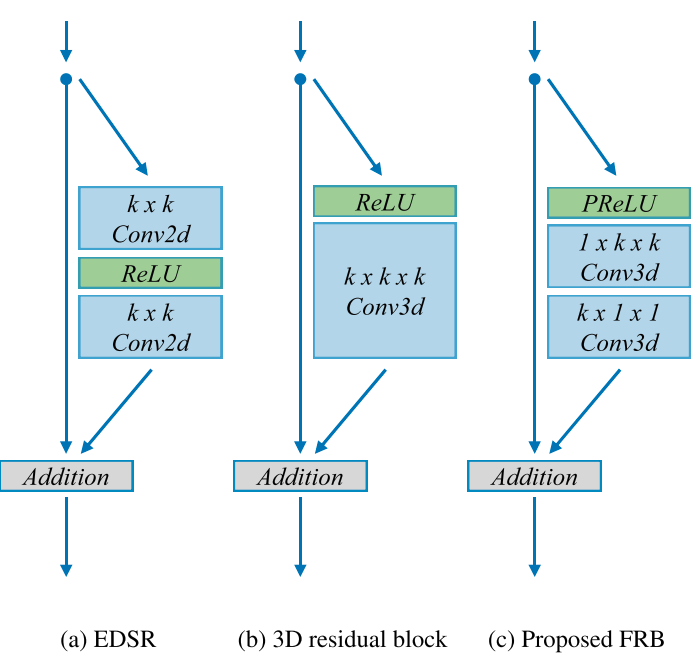
P3D模块由C3D演变而来,C3D使用了3维卷积,所谓3维卷积就是卷积核是三维的,这里对3维卷积做了拆分,如下所示:
在残差连接部分,这里的LRL残差就是在多个FRB后面,将第一个的输入和最后一个的输出相加。CRL是将原始的输入低分辨率图像作上采样,和最后的输出相加。
参考:https://blog.csdn.net/qq_29595303/article/details/97136201