2020 CVPR,和CameraNet那篇论文思路是一样的,都是使用divide and conquer的思路对问题做拆解(ISP和HDR都有人这么玩了,来从成像角度猜猜下一步还有什么low level问题能这么玩)。这里将问题分解成反量化,线性化和伪影去除三个步骤,和其他HDR方法的区别如下图所示:
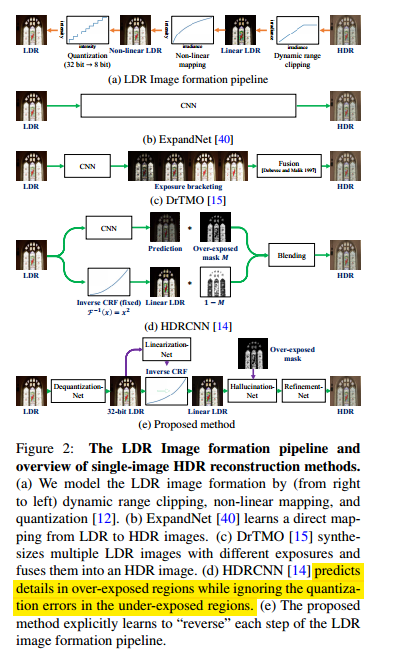
可以看出这里将SDR2HDR拆解成了多个问题去做,这样做很显然会限制求解问题的规模,也是为什么这种基于divide and conquer的思路可以work。首先是反量化网络,这里使用的是一个简单的U-Net网络,loss使用的是L2 loss,该部分的GT是通过HDR转换过来的。
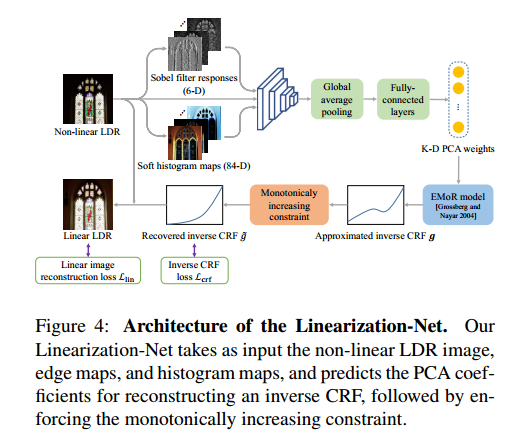
然后是线性化。一般的CRF要确保单调性,以及转换前后的最大值和最小值也是对应的,这里先对inverse CRF进行采样1024个点,然后PCA成11,为了预测inverse CRF,这里需要使用线性为了去得到这个PCA的结果。因为edge和颜色直方图有利于获得inverse的CRF,这里先通过sobel算子获得边缘图,同时通过Spatial-aware soft histogram layer获得具有空间信息的直方图,将这两者送入到网络里,获得PCA权重重建inverse CRF曲线。该部分的loss包括两部分,分别是预测的CRF和GT的CRF曲线的loss,以及线性化结果和GT线性化结果的loss。整个过程如下所示:
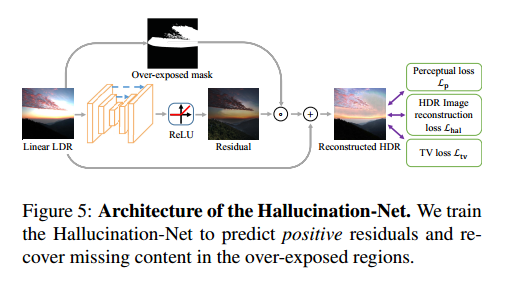
然后是一个去伪影的网络,这里使用一个【0,1】二值的mask去对过曝区域进行处理,并加在原图上从而获得重建的HDR图像。这里的loss包括log域的L2 loss,VGG loss(将HDR tone map到RGB上进行计算)以及TV loss。整体流程如下所示:
最后训练时先对各部分进行训练,然后整体进行finetune。为了进一步处理一些成像中的复杂情况,这里最后还加上一个refine的网络进行训练,部分结果如下所示:
