ZERO-SHOT RESTORATION OF UNDEREXPOSED IMAGES VIA ROBUST RETINEX DECOMPOSITION
出发点是在没有pair对的情况下实现低光图像增强,通过对loss进行迭代来有效估计出噪声和恢复光照,整体结构如下所示:
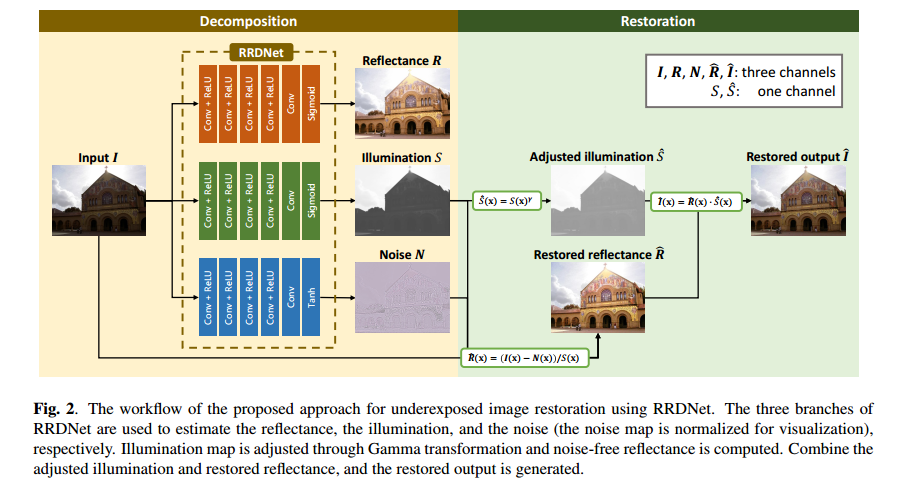
可以看出,网络分别输出三个分支,分别是估计反射图R,估计光照图S和噪声图N。通过将光照图进行伽马变换,以及将输入图减去噪声图N并除以S后进行变换得到估计的反射图,最终可以得到恢复的增强图像。
Loss部分,这里主要包括基于Retinex的重建loss,对光照图的基于WLS的loss,分别如下所示:
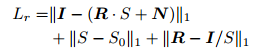
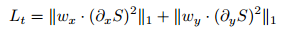
因为需要关注暗光处的noise去除,且对边缘部分尽可能保留,这里基于光照图引导设计了去噪的loss,如下所示:
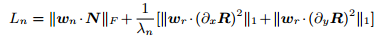
从结果上来看,效果还是可以的,loss设计上也比较合理,但是网络上还有继续改进的空间,在光照图变换和噪声去除上也有继续调整的空间,此外,一边训一边测试的模式,时间开销上可能是个问题,也有可以优化的地方。
RDGAN: RETINEX DECOMPOSITION BASED ADVERSARIAL LEARNING FOR LOW-LIGHT ENHANCEMENT
出发点是目前的增强方法只是对光照图进行操作,忽略了反射图可能也会损失颜色细节等问题(真的是这样嘛),所以这里先进行Retinex分解,得到光照图和反射图,然后将反射图,CRM校正后的图像和输入图送入进一步的处理网络,得到最终增强的效果,如下所示:
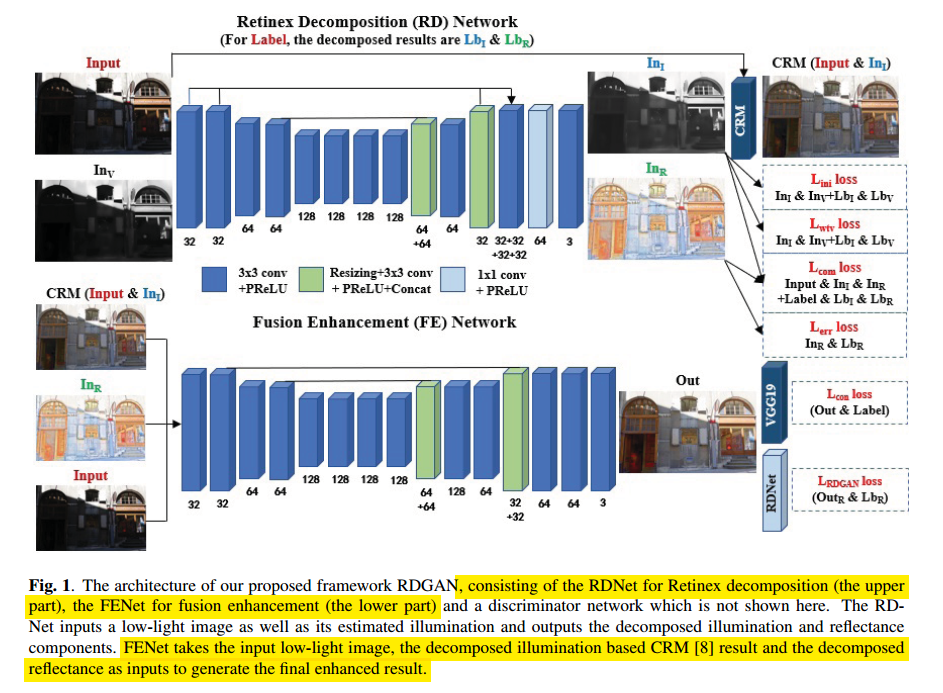
第一步的输入是输入图和粗略估计的光照图,损失函数包括Retinex重建损失,对光照图的WLS损失,对光照图的初始化损失和对反射图的MSE损失。
接着将上面得到的反射图,CRM校正后的图像和输入图送到下面的网络,使用VGG loss和GAN loss作为约束,从而达到更好的效果。
论文看上去视觉效果还OK,这种coarse to fine的思路在CVPR 2020半监督增强思路是一致的,但是这里对于噪声并没有很好的处理,而且两阶段网络可以设计的各有不同,此外,损失函数的设计上也有可以改进的地方。