这是2018cvpr的一篇论文,论文通过提出一个Xunit的结构,使用空间连接的方式,减少模型参数量而没有减少其性能。目前一般的网络通过重复堆叠一般的卷积单元来提高网络的效力,但是这里的Xunit虽然单个单元的计算量比一般卷积单元的计算量要大,但是其可以使用更少的单元去堆叠并获得和很多一般卷积单元相似的效果。Xunit的本质是在每个卷积的激活函数处增加参数,相比于原来只是使用一个relu的没有参数的激活函数,其表现力更强大。
目前减少模型参数的方法主要包括,使用二值的网络,将权重和激活函数都二值化。另外一种方案是使用depthwise卷积,例如Mobienet。还有一种方法是使用pixel-shuffle在超分辨里,以及使用Non-local的方法在去噪任务里。
下面介绍一下Xunit的具体结构,对于一般的卷积,它们包括一个卷积层和作用于每个像素的激活函数,例如relu,分别用来做空间处理和非线性处理,然而这并不一定是low-level问题里最佳的处理方法,也就是说,在激活函数里也是可以加入空间处理单元的。一般的卷积写成如下的形式:
一般的卷积模块和Xunit模块的示意图如下所示,
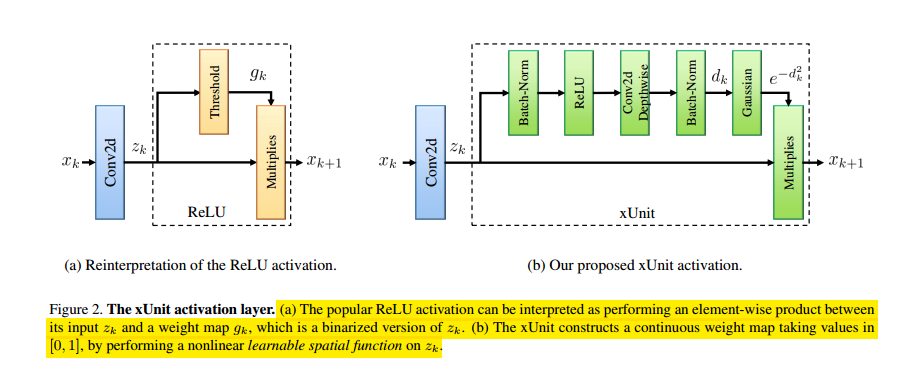
上图中的a图是对激活函数的另一种表示,即这里的非线性激活函数可以看做是一个非线性的pixel-wise的门限单元,这样上面的式子就可以写成:
其中对于relu函数,g又可以表示成$g_k=1 if(z_k>0)$和$g_k=0 if(z_k< 0)$。
这里的Xunit单元,将$g_k$设计成一个依赖空间关系的处理模块。这样$g_k=exp{-[d_k]_i^2}$,以及$d_k=H_kRelu(z_k)$,这里$H_k$是depthwise卷积之后的结果,这个idea的来源包括(1)非线性(relu),(2)空间处理模块(depthwise卷积),和(3)将门限图限制在[0,1]之间(高斯函数)。由于$H_k$是通过depthwise卷积获得的,这里还增加BN层以使网络学习更加平稳。
这里分析一下计算的效能,这里Xunit的带空间处理激活函数,对于一个d通道输入d通道输出,且卷积核大小为rxr的参数量是$(r^2+4)d$,其中rxrxd是depthwise的参数量,4d是两个BN层加在一起的参数量,其相对于一个卷积层rxrxdxd的计算量来说,是相对很少的,所以这也是Xunit参数量比较少的原因。所以虽然一个Xunit单元参数量比一个卷积层略微多点,但是只需要少量的Xunit单元就可以取得和许多卷积单元相似的效果,这还是很划算的。
下面就是分析Xunit的性能,从下图可以看出,使用XUnit的效果在相同参数量的情况下要好于一般的卷积网络,而对于调整depthwise卷积里卷积核的大小,这里的实验发现9x9的卷积核可以达到一个比较好的效果。3层的Xunit(使用卷积核大小是9x9的depthwise单元)网络比9层的卷积网络效果要好,参数量却可以少将近1/3。

从下面的图可以看出,一般的卷积单元学习到的特赠图非常稀疏,而Xunit单元学习的特征图上很稠密,也就是说对于Xunit,更多的特征图参与到了处理任务里。

最后是结果,论文在去噪,去雨和超分辨的三个任务里进行了实验,结论也是自己的参数少的情况下可以达到和一般卷积网络相近的效果,不再赘述。