这是2018CVPR的一篇论文,主要是基于传统的去雾公式嵌入网络。
传统的去雾公式一般基于以下这个公式:
其中,I是观察到的模糊图像,t是转换映射图,J是真实图像,A是大气光散射图,所以去雾的任务就是,给定一张有雾图I,最后恢复出原来的图像J。所以,得到精确的A和t对于去雾任务来说非常关键。但是目前的方法存在两个问题,一个是对t和A的估算并不够准确,一个是无法进行end to end的学习,从而无法发现A和t之间的关系。所以文章的novelty最后个人觉得有三点:1.一个基于去雾公式的端到端的网络;2.一个保边的密集连接的编解码网络生成t;3为了获得去雾后的图和t之间的关联性,使用判别器对它们进行联合训练。下面进行简要介绍:
网络结构
整体的结构图如下所示:
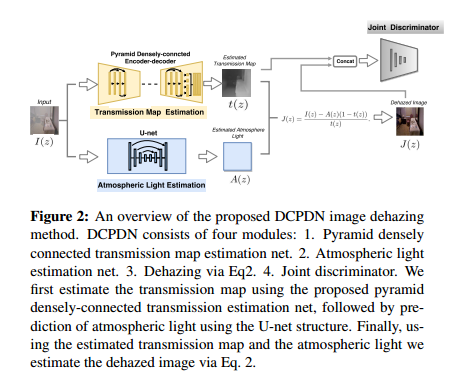
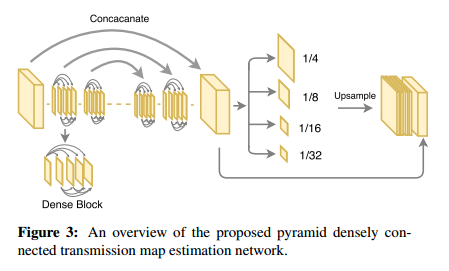
具体而言,对于产生t图的网络,这里采用的是多层金字塔池化模块,这里从densenet里直接取前三个denseblock和相应的下采样层作为encode模块,然后同样使用denseblock进行上采样。这样做的目的是可以通过金字塔池化获得全局的信息,dense模块可以让利于信息流动,加速收敛。同时为了,为了最后的输出获得多个scale的特征,同时保留这些特征的局部信息而不是只获得全局信息,这里使用了一个多scale的pooling层,将不同级别的特征pooling到同一个尺度下,然后进行上采样。网络示意图如下所示:
对于A图像,这里使用一个8 block的U-net结构,具体细节不再赘述。
Joint Discriminator Learning
这里为了获得更真实的输出去雾图和t之间的关系,使用GAN对二者concat一起进行联合学习,从而获得它们之间的内在联系,具体见论文。
Loss
一般认为只使用L2 loss会让图像变得过度平滑,而低级的特征代表了图像的边缘信息。这里使用relu1_2层进行feature loss,同时还加入了输出图和目标图边缘信息(也就是求导图之间)的loss。因此这里的保边loss表示如下(该loss为t图设计):
上式中的三个loss分别表示l2、边缘和VGG loss。
总的loss表示如下:
其中第一项就是上面的$L^E$,第二项是大气光散射图的L2 loss,第三项是输出去雾图和目标图的L2 loss,第四项是GAN的loss。
最后,因为整体网络比较大,这里对各个部分分别进行训练初始化,然后进行联合训练。