线性回归的原理很简单,这里不赘述。使用tensorflow实现线性回归这个功能,麻雀虽小,五脏俱全。主要包括以下几个部分:
1、产生数据。
2、声明输入变量和待学习的变量。
3、定义运算节点,也就是如何得到预测值。
4、定义损失函数loss。
5、对损失函数进行优化。
和网上一般的教程不一样,这一次我使用tensorflow的supervisor功能进行迭代训练,在迭代过程中调用matplotlib库实时画出线性回归学习的过程,使用argparser方便变量传入。代码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import tensorflow as tf
import logging
import numpy as np
import matplotlib.pyplot as plt
import argparse
import os
logging.basicConfig(format="[%(process)d] %(levelname)s %(filename)s:%(lineno)s | %(message)s")
log = logging.getLogger("train")
log.setLevel(logging.INFO)
# 产生数据
N = 200
x_data = np.linspace(-1, 1, N)
y_data = 2.0*x_data + np.random.standard_normal(x_data.shape)*0.3 + 0.5
x_data = x_data.reshape([N, 1])
y_data = y_data.reshape([N, 1])
def log_hook(sess, log_fetches):
data = sess.run(log_fetches)
step = data['step']
loss = data['loss']
log.info('Step{} | loss = {:.4f}'.format(step, loss))
def main(args):
x = tf.to_float(x_data)
y = tf.to_float(y_data)
W = tf.Variable(tf.random_normal([1,1],stddev=0.1))
b = tf.Variable(tf.random_normal([1],stddev=0.1))
pred = tf.matmul(x, W) + b
loss = tf.reduce_sum(tf.pow(pred - y,2))
global_step = tf.contrib.framework.get_or_create_global_step()
train_op = tf.train.GradientDescentOptimizer(args.learning_rate).minimize(loss,global_step=global_step)
tf.summary.scalar('loss',loss)
log_fetches ={
"W":W,
"b":b,
"loss":loss,
"step":global_step}
sv = tf.train.Supervisor(logdir = args.checkpoint_dir,save_summaries_secs=args.summary_interval,
save_model_secs=args.checkpoint_interval)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with sv.managed_session(config=config) as sess:
sv.loop(args.log_interval,log_hook,(sess,log_fetches))
while True:
if sv.should_stop():
log.info('stopping supervisor')
break
try:
WArr, bArr, _ = sess.run([W,b,train_op])
plt.scatter(x_data, y_data)
plt.scatter(x_data, WArr*x_data+bArr)
plt.pause(0.3)
plt.cla()
except tf.errors.AbortedError:
log.error('Aborted')
break
except KeyboardInterrupt:
break
chkpt_path = os.path.join(args.checkpoint_dir, 'on_stop.ckpt')
log.info("Training complete, saving chkpt {}".format(chkpt_path))
sv.saver.save(sess, chkpt_path)
sv.request_stop()
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--learning_rate', default=1e-3, type=float, help='learning rate for the stochastic gradient update.')
parser.add_argument('--checkpoint_dir', default='summary/', help='directory of summary to save.')
parser.add_argument('--summary_interval', type=int, default=1, help='interval between tensorboard summaries (in s)')
parser.add_argument('--log_interval', type=int, default=1, help='interval between log messages (in s).')
parser.add_argument('--checkpoint_interval', type=int, default=20,help='interval between model checkpoints (in s)')
args = parser.parse_args()
main(args)
点击运行,效果如图所示(左边是开始时,右边是训练完成,可以实时显示变化过程):
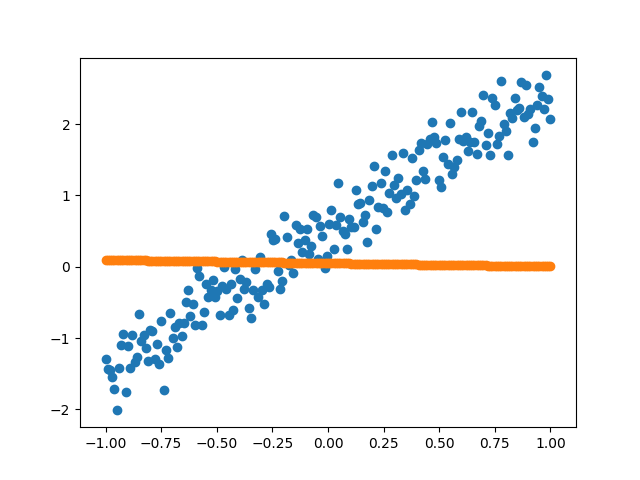
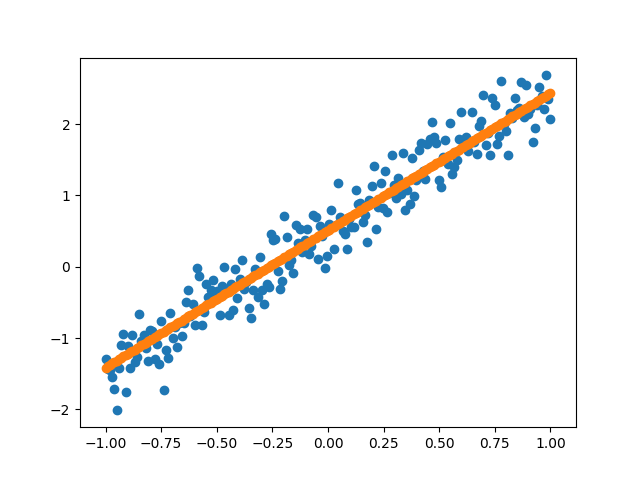
下面具体进行分析。
matplotlib画出动态图
这里先用plt.scatter()画出散点图和拟合的直线图,然后通过plt.pause(0.3)使图像停留0.3s再更新,最后通过plt.cla()删除刚才图上的点和线,这样可以避免上一次的轨迹遗留到下一张图上。
argparser功能
这里我通过argparser解析器传入一些参数,argparser的一般使用步骤如下:1
2
3
4import argparse
parser = argparse.ArgumentParser()
parser.add_argument("echo")
args = parser.parse_args()
“echo”里的内容一般有以下:
(1)name or flags:命令行参数名或者选项,其中命令行参数如果没给定,且没有设置defualt,则出错。但是如果是选项的话,则设置为None
(2)nargs:命令行参数的个数,一般使用通配符表示,其中,’?’表示只用一个,’*’表示0到多个,’+’表示至少一个
(3)default:默认值
(4)type:参数的类型,默认是字符串string类型,还有float、int等类型
(5)help:解释该参数的作用和意义
注意:name or flags里的内容前面一定要加上”—“符号否则参数会无法导入!
logging功能
logging用来输出日志,print也可以输入日志,logging相对print来说更好控制输出在哪个地方,怎么输出及控制消息级别来过滤掉那些不需要的信息。
这篇代码里,使用Logging的几个地方含义如下:
(1)logging.basicConfig(format=”[%(process)d] %(levelname)s %(filename)s:%(lineno)s | %(message)s”)
这里使用logging.basicConfig函数对日志的输出格式及方式做相关配置。
(2)log = logging.getLogger(“train”)
logger可以提供日志接口,供应用代码使用。可以通过logging.getLogger(name)获取logger对象。
(3)log.setLevel(logging.INFO)
指定日志的最低输出级别,默认为WARN级别,这里默认最低为INFO,低于它就不输出了。
(4)log.info log.error
日志级别的两种,一般有以下几种:
debug : 打印全部的日志,详细的信息,通常只出现在诊断问题上
info : 打印info,warning,error,critical级别的日志,确认一切按预期运行
warning : 打印warning,error,critical级别的日志,一个迹象表明,一些意想不到的事情发生了,或表明一些问题在不久的将来(例如。磁盘空间低”),这个软件还能按预期工作
error : 打印error,critical级别的日志,更严重的问题,软件没能执行一些功能
critical : 打印critical级别,一个严重的错误,这表明程序本身可能无法继续运行
更多关于Logging可以参考网上的博文。
参考:
1、https://blog.csdn.net/freedom098/article/details/56280865/
2、https://blog.csdn.net/Sunshine_in_Moon/article/details/51332931
3、https://www.cnblogs.com/CJOKER/p/8295272.html