这里简要略读了今年CVPR workshop的一些论文,下面依次介绍大致的思想。
NTIRE 2019 Challenge on Image Enhancement: Methods and Results
这个challenge使用的是真实的手机图片对,所以其包含的不仅仅是色彩光照等的增强,还包括去噪、边缘增强等等。这里报告指出一些队伍在低分辨下的指标不错,但是在全分辨图片下效果较差。所以后面工作里还要注意自己算法的鲁棒性。这里简要介绍前几名的方法。
第一名的方法是我前东家美图采用的,使用的是多层级的Unet的结构,这里包括一个encoder,一个decoder,一个多层级下采样层,一个HRNet模块,encoder是三层网络,然后依次下采样三次,并送进HRNet模块,并上采样相加,最后送进decoder。看最后结果其MOS比较高,猜测应该是用了基于IQA的评价器做了优化,虽然报告里没提。
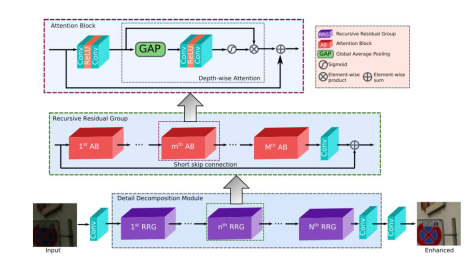
第二名的方法是使用的五个递归模块,每个模块有十个attention block,如下图所示:
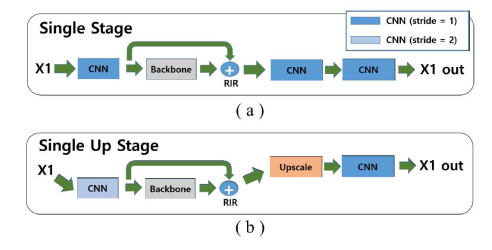
第三名的方法是使用了两个步骤,首先下采样送入下面的b里面,然后上采样并和输入图结合送到a里面,我理解第一步在低分辨空间做可以获得图像的特征信息,过程类似于deep boosting的结构。如下图所示:
第四第五名使用的分别和FOCNet和DBPN相似的结构,不再赘述。
Histogram Learning in Image Contrast Enhancement
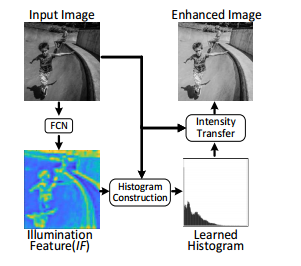
这篇论文要解决图像不同区域对比度不同的问题,基本思想是获得图像光照图的特征,然后根据光照图特征获得其预测的区域直方图,并使用直方图转换将预测的转换结果施加到输入图上,实现图像增强。如下图所示:
Content-preserving Tone Adjustment for Image Enhancement
这篇论文的思路是先学习一个全局转换器在原图上进行原图转换,然后进行局部转换,整个流程图如下所示:
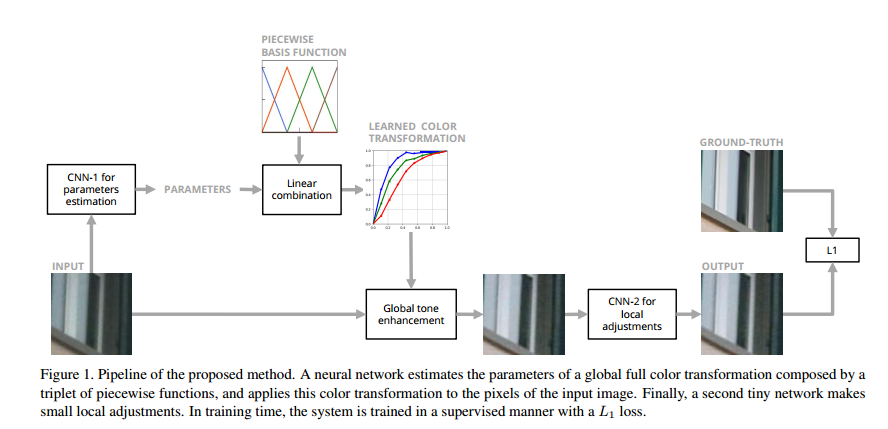
全局转换器的系数通过一个下采样网络学习得到,这里转换器详情参考论文。调整好的图像再送入局部转换器,其由少量几个卷积层组成。之所以分成分成两步,是因为目前的增强数据集分成两大类,完全对齐的和有像素偏移的,对于前者只需要使用第一步,对于后者需要同时使用两步,两者的卷积核形式分别如下:

可以看出完全对齐的数据集卷积核都集中在一个点,所以可以借助全局转换实现得到。
Optimization-Based Data Generation for Photo Enhancement
这篇论文没怎么看懂,是一个做图像增强数据集的方法,针对原有的优化方法做了改进。结构图如下所示:
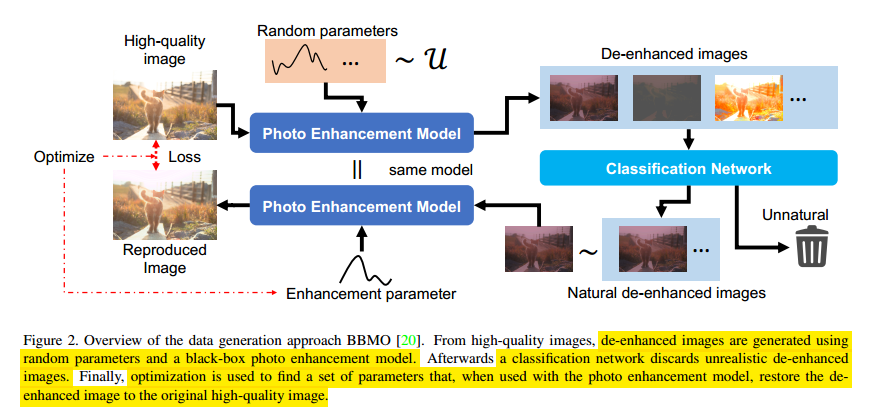
首先使用随机参数施加到增强模型里,使得原图像变成低质量图像,然后使用分类网络将生成的低质量图像中非自然的部分去掉,剩余的图片通过增强模型的反过程恢复出原来的图像(参数和正向贡献),通过loss施加输出的图像和输入的图像相似,从而学到降质参数。论文重点阐述的是优化过程。
Multi-stage Optimization for Photorealistic Neural Style Transfer
这篇论文做的是照片风格迁移,主要思想是将一般的全局风格迁移方法和加mask的迁移方法相结合,减少生成图像的artifact。流程图如下所示:
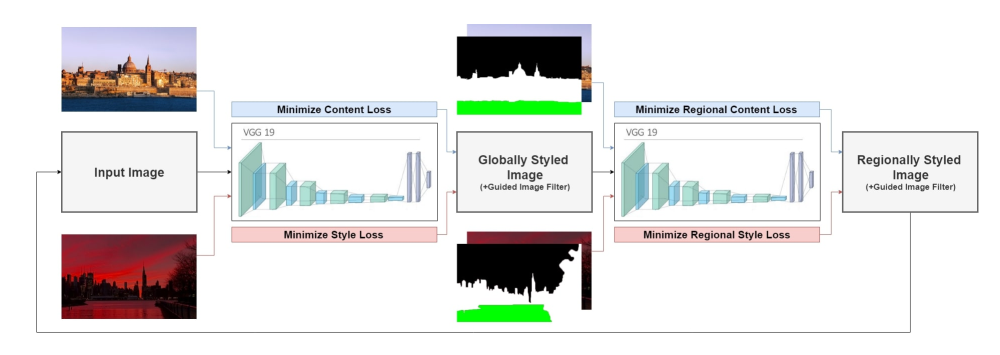
可以看出整个过程分成两步,第一步使用的一般transfer的全局转换,第二步使用加mask的区域转换,两个步骤迭代进行,使用的都是VGG loss和风格loss。
总结这些论文可以发现很多都是将问题的解分成多个步骤去做,后面的工作可以借鉴它们的思想。