2019 CVPR一篇做风格迁移的论文。这篇论文和前面一样,也是注重于对内容的转换。这里在encoder和decoder之间加入内容转换模块,可以控制风格并达到对风格感知的内容edit。在对内容进行调整时,这里需要对特定的物体达到特定的效果,所以这里还利用相似的内容在照片和风格sample里去学习风格如何改变内容,进一步,其将特定的物体扩展到了更广阔的内容里。同时提出一个局部特征正则层去减少artifact和增加分辨率。整体流程图如下所示:
令D是decoder,E是encoder,Y是转换到的风格域,X是输入,那么首先判别器要无法区别真实的风格和生成图像的风格,并且保证场景信息能够保留,所以有:
其次要使得生成图像和输入图像的像素具有内容一致性:
当然生成图像和原来的图像不能完全的像素相同,在确保内容相同的条件下,这里要使得它们在encoder空间的形式相同,表示为:
Content Transformation Block
不同的内容需要被不同的style,所以这里通过从参考风格化的图像里找到相似的内容进行转换。这里通过将encoder的输出通过内容转换模块实现,通过一个判别器去分开真实风格图片的内容和转换图片的内容,在给定内容类别c的前提下,表示如下:
其中转换模块$\tau$表示为9个残差模块concat在一起。
Local Feature Normalization Layer
这个层不是对整个tensor进行归一化,而是进行的局部操作,这里选取一个window进行归一化操作。详情见论文,同时减少了计算量。
Training Details
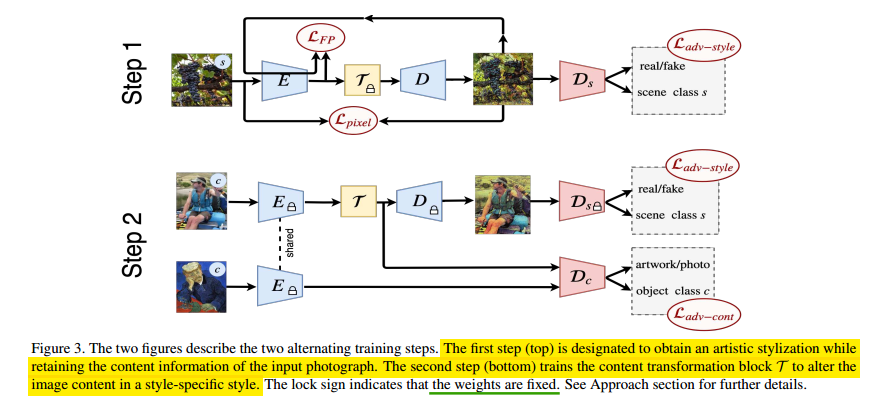
训练细节如上图,分为两步。这里关注的内容类别是人,所以分为人和非人两类。两步分别如下:
首先第一步是获得从encoder精确获得的内容提取和学习decoder的注入style,目标如下:
其中最后一项是上面的$L_{cadv}$。
第二步是通过转换模块学习特定的style获得特定的内容,如下: