2019CVPR的一篇论文,做的是少样本色彩化。解决的是样本数量小,且容易忽略较少个例的问题,即只关注主要的颜色迁移而忽略次要的色彩迁移。所以这篇论文的要点是使用少样本,可以进行少样本上色,借鉴memory网络里从训练集里给定的颜色信息,通过查询的方式获得这些信息。并且使用一个triplet loss,使得其可以以无监督的方式进行。整体结构图如下所示:
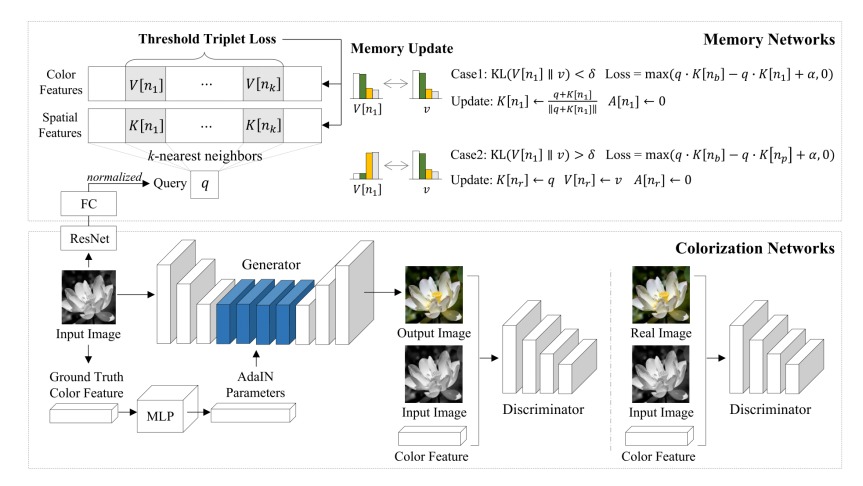
从上面可以看出,整体结构由memory网络和上色网络组成。其中前者可以记忆少样本的个例
并产生色彩化效果,后者负责进行上色,两者分别如下:
Memory Networks
在记忆网络里,这里存储三个类别的信息,分别是key、value和age,这里key(K)是存储了输入信息的空间特征,key网络用来计算和输入查询的cosine距离,value(V)存储颜色信息可以用来为上色网络提供条件,age向量A存储记忆网络里被使用的先后顺序,总体结构可以表示为:
其中m代表记忆网络容量,查询值q是首先将输入图送进一个预训练好的resnet网络里获得,最终获得输出的空间信息X,同一类物体被归为一类。然后将获得的特征X通过一组可学习的参数W和b,最后对查询值q进行归一化,得:
获得这个q后,记忆网络计算和q最接近的k个K,并返回最接近的值V[n1],用以上色。对于颜色特征,这里从两个角度从value里面获得,首先是颜色分布LAB,对其进行量化到313个颜色值得到C{dist},另一个是RGB颜色值,其包含十组值,称为$C{RGB}$,这里使用$C{dist}$来代表value的值。
这里接着使用triplet loss,去最大化查询值和正样本key的相似性,最小化查询值和负样本的相似性。但是这一般需要有标签,即需要获得的最近的value值$V[n_p]$和输入查询值q是相同的类别,显然这里没有类别的。所以这里使用的设定是,如果给定两个图片具有近似的空间特征,如果它们的颜色特征在一定范围内,那么就认为它们更可能是一个类别。这里令输入图片的真实颜色特征为v,查询获得和v接近的记忆网络里的颜色信息$V[n_p]$,$n_p$是所有正样例索引值,正样例V和查询得到v此时满足$KL(V[n_p]||v)<\sigma$,同理负样例所有的索引值为$n_b$,此时满足$KL(V[n_b]||v)>\sigma$,最终loss表示为:
即这里的loss希望负样例和查询结果的差异大,正样例和查询结果的差异小,这显然是符合常识的。
然后是进行记忆更新,这取决于最接近查询值v的颜色信息$V[n_1]$和v是否在阈值范围内,如果在,即$KL(V[n_1]||v)<\sigma$,这里就对$K[n_1]$使用q进行更新,并进行归一化,同时age也更新为0,如下所示:
如果是$KL(V[n_1]||v)>\sigma$,说明记忆网络里找不到与现有颜色特征相似的样例,这个时候需要借助现有颜色特征进行更新,这里从age最大的索引里随机找出一个值$n_r$,然后进行更新为目前的索引(q,v),这里更新表示为:
Colorization Networks
首先是损失函数,这里使用的是cGAN,详情见上面的图,使用颜色特征作为条件,具体不表。此外还使用了L1 loss,这里也具体不表。在训练时,颜色特征从GT里获得作为条件,在测试时,颜色特征从记忆网络里获得。测试结构如下图所示:
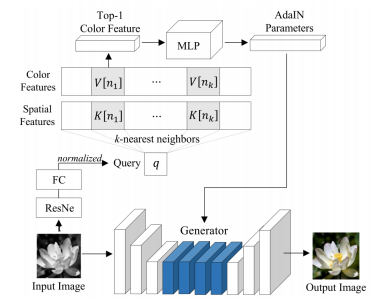
颜色作为一种style,可以使用AdaIN进行着色,以这种方式作为颜色条件,AdaIN表示为
其中z是前面卷积的相应值,放射系数通过颜色特征变换得到,具体不表。