虽然之前也看过一些图像去模糊的论文,但是看的比较少。最近的工作因为和去模糊相关,所以快速的浏览了其他一些去模糊的工作。非常简要写在这里。
A Deep Motion Deblurring Network based on Per-Pixel Adaptive Kernels with Residual Down-Up and Up-Down Modules(CVPR workshop 2019)
论文主要思想是认为图像的运动幅度大小造成的模糊是不同的,对于小的模糊可以使用KPN去解决(可以有效滤出损失的信息),对于大的模糊可以使用Residual去学习。因此一个策略是将两者结合在一起。另外一个是使用RDU和RUD模块,和DBPN里的模块比较像,RDU用在encoder而RUD用在decoder(当然也是试出来的)。整体的pipeline如下图所示:
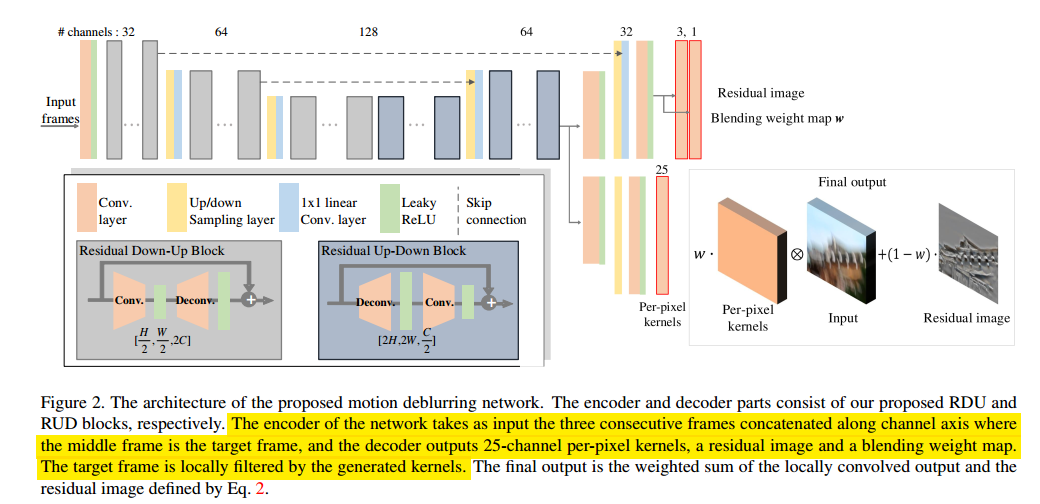
Region-Adaptive Dense Network for Efficient Motion Deblurring(AAAI 2019)
使用的结构依然是基于U-net的,整体结构如下(最后使用类似ASPP的结构获得不同感受野):
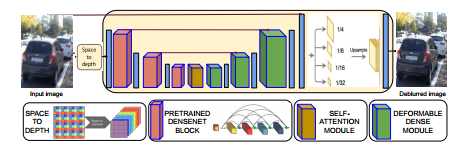
论文的核心思想是模糊是非均匀的,因此应当使用空间各异的卷积去有效扩大感受野。所以这篇论文里使用类似于STN的模块,放在网络的decoder部分,用来重建去模糊后的图像,该模块由多个deformable conv稠密连接得到,有效应对非均匀模糊,如下图所示:
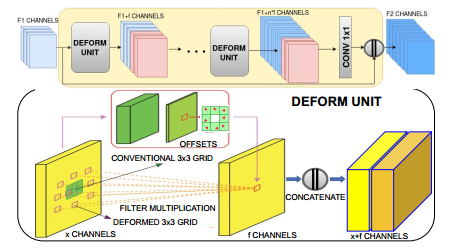
在encoder和decoder中间的部分,是一个SA模块,可以看做是nonlocal的一个2D版本,可以获得长短距离像素之间的关联性,如下图所示:
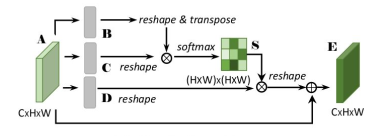
Deep Stacked Hierarchical Multi-patch Network for Image Deblurring(CVPR 2019)
一张图如下,直接参考其他人的博客就OK: https://blog.csdn.net/avinswang/article/details/90756495 和 https://blog.csdn.net/gwplovekimi/article/details/93058810
