这是2018 ECCV的一篇论文,主要阐述使用GAN对特征进行训练,这里只做简要的介绍。
文章的目的也是为了获得具有较高感知质量的高分辨图像。目前基于GAN的SR方法很难产生具有有意义的高频信息,这是因为SR之后的图像和真正的HR图像之间的差别还是它们的高频信息,L2 loss不利于学习高频信息,而直接的GAN loss则会产生随机的噪声。所以这里使用了GAN也对特征进行GAN的学习。
网络结构
网络的基本结构是resblock,其有一个3x3的卷积,BN层,leakyrelu层,3x3卷积,BN层依次串联,总共有16个残差模块。这里对生成器的改进就是将网络中间层的特征全部通过1x1通道变换之后放到最后concat在一起,从而对这些中间特征进行重复利用,网络结构图如下所示:
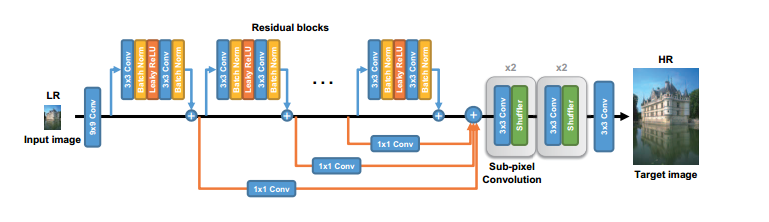
预训练
首先对网络使用L2 loss进行预训练,不再赘述。
GAN训练
这里的loss形式表达如下:
其中第一项$L_p$表示VGG特征图上的特征loss,$L_a^i$表示生成图和目标图的generator loss,$L_a^f$表示生成图和目标图在VGG特征上的generator loss,判别器loss这里不再赘述。
这篇论文比较水,这里就写这么多。