这是2018 CVPR一篇做图像去雨块的论文。图像去雨块的困难在于,雨块的去雨并没有被标记出位置,且雨块覆盖的位置存在信息缺失。因此文章的思路是,首先通过生成网络生成一个attention map,指导下一步的去雨工作,使得下一个阶段生成网络注重于有雨块的区域,这个map是通过一个递归的resnet网络借助LSTM实现的。然后是一个编解码网络,其将输入图和attention map一起输入。这里使用了多尺度的Loss获得不同尺度的语义信息,以及最后编解码网络输出,最后网络的输出图和gt利用VGG和GAN分别做loss。雨块的问题公式表示如下:
其中,M是一个二值掩膜,B是背景图像,而R是雨滴效果。雨滴区域里透明的地方是可以反映背景信息的,这部分信息可以通过网络学习得到,受到M的启发,这里使用attention map去引导网络进行去雨,学习图像的雨块区域。整体结构图如下:
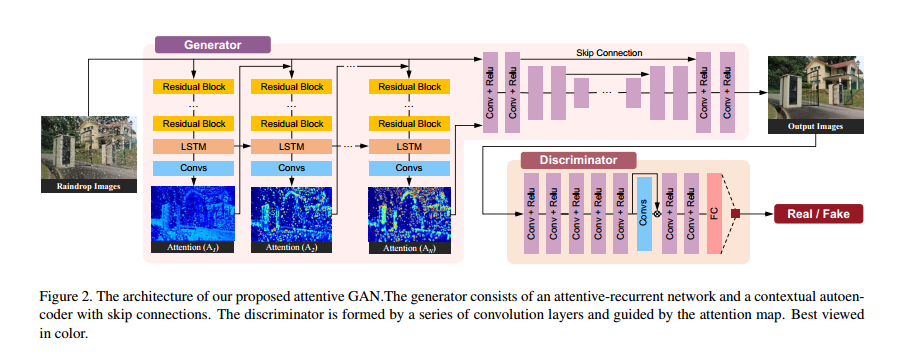
Attentive-Recurrent Network.
这里使用一个递归的神经网络去生成attention map。每一个time step包括五个res block提取特征,一个卷积LSTM和一个卷积层用来生成2D的attention map。生成的这个map值在0到1之间,越大代表区域越被关注。这个map表示了一个attention区域从没有雨到有雨的一个过程,雨块内部的值也是不同的。这是因为雨块周边的区域也需要被attention,雨块的透明度也不相同。
LSTM和下面的卷积生成一个2D的attention map,这个map初始化设定值为0.5。在每一个时间step,将上一阶段的attention map和输入图concat作为下一个时间step的输入。最后这个递归网络的loss被定义为如下:
这里At是t时刻的attention map,M是二值掩膜,N是总共有N次step,$\theta$是0.8,这个loss表示在这一步中两幅图片的不匹配程度。实验得到,在迭代的过程中,attention map中有关雨块和其结构化的信息越来越多。
Contextual Autoencoder.
这部分的目的是用来生成最后的输出去雨图,输入是输入图和attention map concat在一起之后。这里有一个多尺度的loss,就是将decoder的层的feature转换到输出维度和下采样之后GT做MSE,从而获得不同尺度的语义信息。此外对最后的输出和GT还做了一个基于VGG的feature loss,最后的loss可以表示为:
第一项是GAN loss,第二项是attention的loss,第三项是mutiscale的loss,最后一项是feature loss。
Discriminative Network
这里的判别器需要对局部进行学习,判断哪些区域为真,哪些区域为假。但是这里并没有先验的信息来告诉我们哪些位置可能为假,因此需要判别器自己去学。因此这里引入了前面的attention map,这里从判别器中提取特征送到一个CNN,CNN的输出和attention map做loss,再乘到CNN的输入,在送到下一层之前
。做这一步的目的是使得判别器关注被attention map指出的区域。最后一个FC来表明图像是真还是假。
判别器的loss被定义为GAN loss和这个feature loss之和,具体不表。