这是2019 CVPR一篇做stereo deblur的一篇论文,这里简要介绍一下思路。
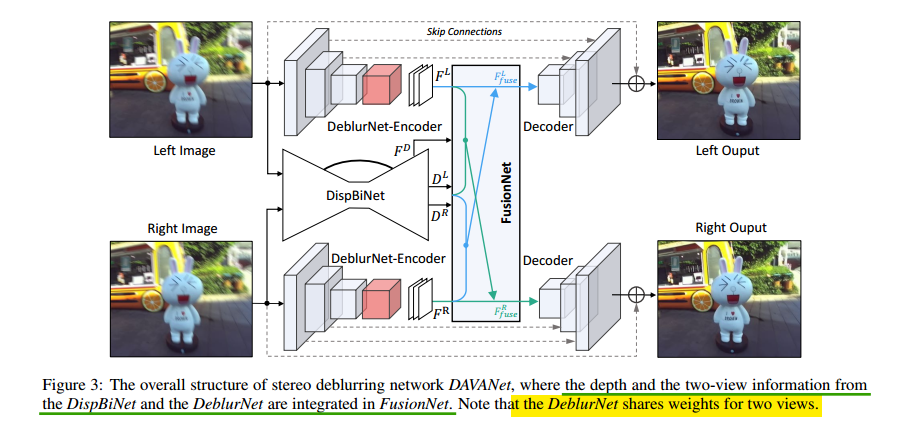
使用双目做deblur的原理是,两张图像获得的blur是不同的,blur具有非常大的空间变异性。(1)深度信息可以提供额外的先验信息;(2)两张图像想不同的信息可以帮助去除模糊。即论文的两个motivation是,首先近距离的物体比远距离的物体更容易blur,通过距离信息可以获得更好的估计出区域blur的大小;此外,两个角度的相机会产生不同的blur,边缘视角可以更好的帮助另一个视角恢复。论文的网络包括,deblurNet用于去模糊,dispBiNet用于获得深度和视角信息提供给FusionNet,而FusionNet利用这些deblurNe和dispNet提供的信息做融合利用。整体网络结构图如下所示:
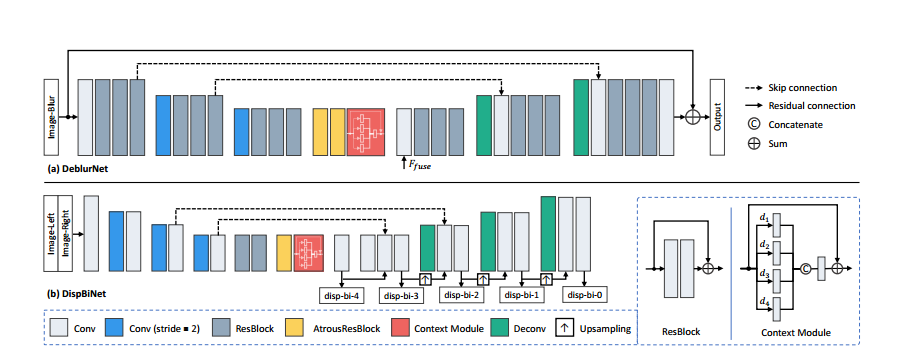
对于deblurNet,这里使用的是一个UNet的架构,这里为了获得更大的感受野,在encoder和decoder之间使用两层空洞卷积。这里DispBiNet可以预测双向的深度,在这个过程中使用三次下采样和三次上采样。为了获得多尺度特征这里还为这两个网络加入了类似于ASPP的结构,这两个网络的结构如下图所示:
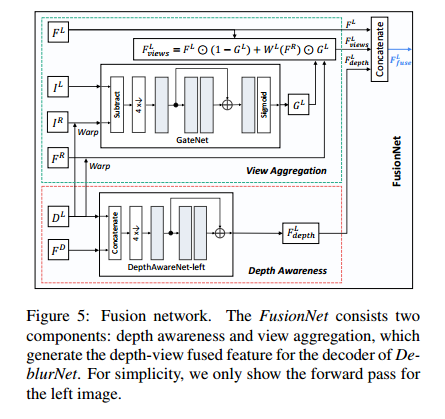
对于FusionNet,以左边为例,输入是左右两张图,估计的左深度图,从DispBiNet第二层来的深度特征,以及从deblurNet的encoder过来的左右图的特征图。首先将左深度图和右特征图warp到左视角,得到$W^L(F^R)$。然后将左图和warp到左视角的右图的绝对值之差$|I^L-W^L(I^R)|$,送到一个GateNet生成gate map $G^L$,范围是0-1之间。其可以用来自适应的融合左特征和warp到左视角的右特征,也就是说其可以选出有用的特征和过滤掉没有用的特征。例如对于错误区域,其值大小为0,也就是说该区域使用左特征就好了(这一点和CVPR2019那个做多曝光增强的论文很像)。这一点对应于第二个motivation,即利用另一个视角的信息,融合表达式如下:
对于第二个motivation,即利用深度信息,这里DepthawareNet输入是估计出的做深度图和从DispBiNet第二层来的深度特征,两者concat在一起作为输入。最后输出depth的先验特征,更好帮助去模糊。在FusionNet的最后,depth先验特征和左特征、$F_{views}^L$ concat在一起,送到decoder里。FusionNet的结构如下所示:
对于Loss,这里包括输出图和目标图的MSE loss,以及它们基于VGG的feature loss。为了获得深度图,训练DispBiNet使用输出的估计深度图和目标深度图的MSE loss。其他部分见实验。