这是2018年 cvpr的一篇论文,思路和去年我做毕设的思路很像(看来科研idea冲突的例子还是很多的)。这里简要说一下其思想。
首先论文认为许多图像处理问题其实是在做两个部分的估计,分别是结构部分估计和细节部分估计,也就是低频部分和高频部分。比如目前的残差学习,其主要就是假设低频结构已经给定,通过网络去学习获得高频细节。同时通过网络去同时学习低频区域和高频区域是一件很有挑战性的事情,此外当低频结构信息没有很好的保留时,残差学习的方法并不会work的很好。
论文的网络是分成两个部分,分别是S网络学习低频的结构信息和D网络学习高频的细节信息,然后将两个部分的输出组合起来,网络结构如下:
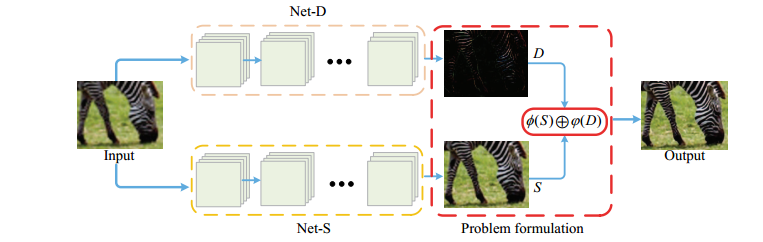
S网络和D网络的输出分别为S和D,则最后的输出是$X_{est}=\phi(S)+\Phi(D)$,其中$\phi$和$\Phi$根据任务需要的领域知识不同而不同。最后的loss是以下三个部分的组合:
其他部分详见论文。