这是2018 TIP的一篇论文,做的是单图多曝光图像增强,这里简要谈一下我的理解。
论文的目标是弄出一个单图多曝光图像融合同时避免产生artifact,实现图像的对比度增强。论文通过STOA的HDR方法生成参考的高质量图片。因此论文原始的Idea是使用一个15层的卷积直接学习输入低对比度和参考图的映射。Loss分别使用L2 loss,L1 loss和SSIM loss。但是一个stage的CNN很难很好的增强图像的细节和纹理信息。这里根据Retinex理论,图像的低频信息代表全局自然程度,而高频信息代表图像的局部细节,所以很自然的就是把低频信息和高频信息分开来(特么和我去年毕设思路完全一样啊)。低频部分可以用来增加对比度,而高频部分可以用来增加细节,所以这里设计两个网络对它们分别进行处理。图像送入之前使用WLS滤波器分成低频和高频两个部分。两个网络处理的结果进行融合,然后进行再增强,结构图如下所示:
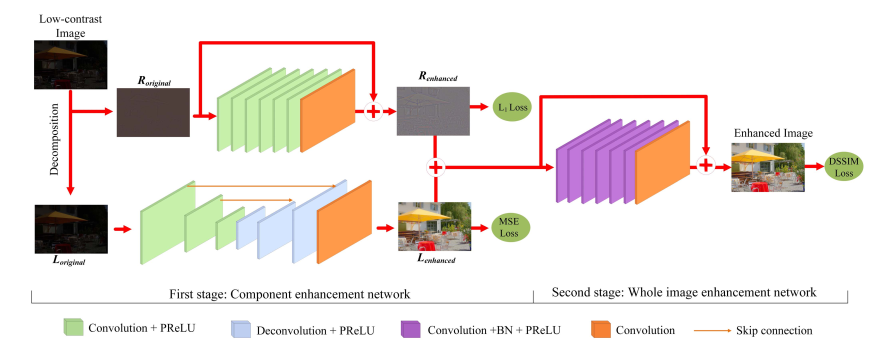
如上图所示,这里发现对于低频部分这里使用卷积加padding的方式会导致周围出现artifact,所以这里采样stride卷积和反卷积的方式,减少artifact同时也减少计算量,并增加了感受野。同时,因为因为特征图的正值和负值都包括重要的结构信息,所以使用Relu不妥,这里使用Prelu。对于低频部分,这里可以学习到光照,该部分Loss设计为网络输出和参考图的低频部分,表示如下:
对于高频部分,这里采用的是残差学习的方式,训练更稳定,这里使用输出结果和参考图和高频部分的L1 loss,因为高频部分分布遵从laplace分布,并且会包括噪声和一些轮廓信息,表示如下:
但是两部分分别得到的结果直接相加不能保证最终结果视觉质量是好的。这里最后对两者结果进行融合,网络和细节增强部分相同,除了增加了BN。训练时,前面低频和高频网络分别进行训练,然后固定参数训练融合网络,融合网络的loss为输出图和参考图的SSIM loss,如下所示:
其余部分参考论文。