这是2015 ICCV的一篇论文,很老的一个论文,这里简要谈一下我的理解。
一种彩色化的思路是将图像和数据库中的参考图像进行比对,从中迁移最接近的patch和pixel的颜色信息到目标域上。这里将图像彩色化作为一个回归问题,使用深度网络去解决这个问题。由于图像彩色化通常是语义感知的,所以这里使用语义描述子去在彩色化模型里包含语义感知信息。整体结构图如下所示:
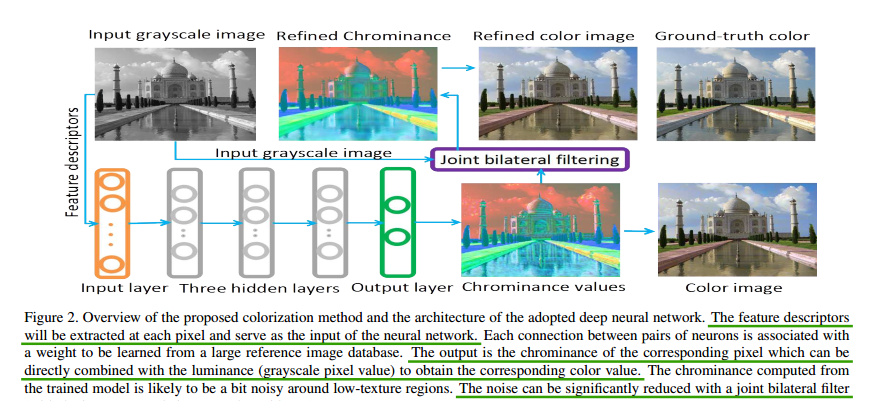
如上图所示,整体框架是先获得特征描述子,这里将获得的特征分为低级别特征、中等级别特征和高级别特征。然后将这些特征做一个concat。对于低级别特征,这里使用亮度分量的特征去表示,其和色度信息没有关系,用一个7x7的patch中心的连续序列去表示低级别特征。对于中级特征,这里使用DAISY去做局部描述。对于高级别语义特征,这里的语义图使用N维的概率向量去描述,使用其可以避免二义性。这里没有使用全局特征,因为全局特征会使用参考图像里全局相似度高但是语义不一致的图,从而产生不自然的结果。
输入是上述特征的组合,这里可能会产生artifact,对此论文给的解决方法是使用双边滤波,去对色度图做一个平滑。以往的STOA方法非常依赖参考图像的选择,这里使用数据库中比较接近的像素并将其颜色迁移过去。其余部分见论文。