这是2019 CVPR的一篇论文,做的是图像盲SR,感觉做的优点意思,这里简要谈一下我的理解。
论文使用的策略是更好的估计造成下采样的模糊核,因为如果模糊核估计的不好,例如估计的比真实的要光滑,那么输出图像就会变得更平滑,反之会变得更尖锐。所以这里通过迭代的调整估计的模糊核,使得输出图像和真实GT更接近。此外论文发现使用特征转换SFT比把模糊核和输入图一起送进去效果要好。论文使用的下采样是高斯模糊和三次插值下采样模糊的结合。
论文的优化目标是使得估计的模糊核k’和真实的模糊核k尽可能接近,如下所示:
其中$\theta_C$是需要优化的参数,C是校正函数,该步是通过中间输出的SR结果$I^{SR}$和GT尽可能接近来实现的,整体网络结构图如下所示:
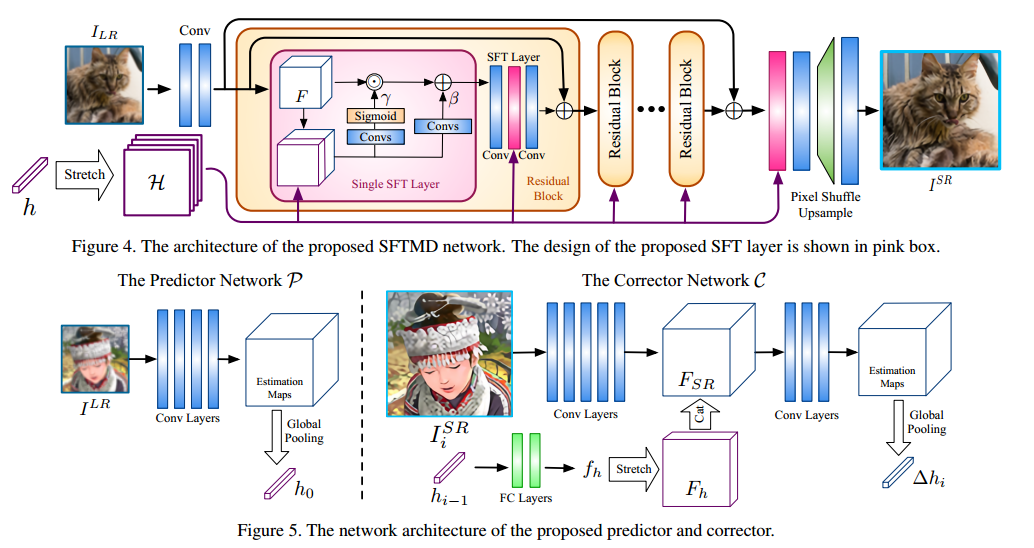
如上图所示,首先对模糊核做PCA处理进行降维,降维后变成h,当然因为模糊核是迭代生成的,初始的模糊核通过LR图像直接生成,令为$h_0 = P(I^{LR})$,接着按照下面算法迭代生成输出的SR图像和估计的模糊核,如下所示:

论文认为模糊核的内容和图像无关,所以两个在一起使用卷积处理会引入和图像无关的信息。同时模糊核也不能只影响其中一层,还需要对其他层也进行影响,这里通过SFT进行特征转换实现,表示如下:
其中F是前面层的特征,两个参数通过小的CNN获得,输入是h和前面层的特征concat在一起得到,现当于做了一个attention。对于h的获得,这里通过输入图像卷积得到的特征图,做全局平均池化得到,如上图所示。其他部分详见论文。