刚挂出来的一篇论文,针对DPED数据集做的增强,一些loss比较有意思。整体结构如下所示:
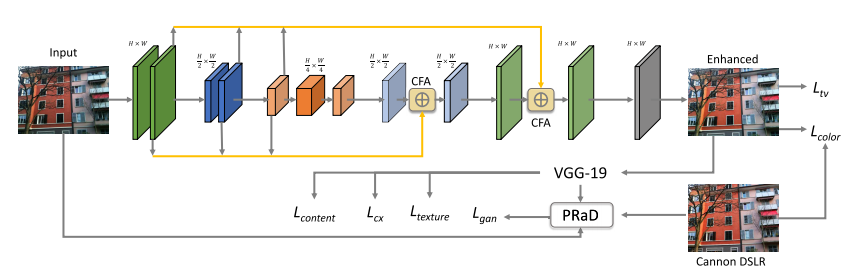
网络结构上没什么好说的,基本结构是一个UNet的一个架构,对于encoder不同的scale上的特征,其进行相应的上下采样和对应的decoder的特征concat在一起(类似于dense的方式),即上面的CFA模块,ecoder在和encoder concat之前先卷积一下减少反卷积效应。总之这个结构不复杂。
关于loss方面,这里包括color loss,即目标和输出的L2 loss,contet loss即基于VGG的loss,TV loss,梯度loss,即输出和目标梯度图之间的loss。局部对比度loss,这个loss先计算一副图像里面窗口区域的均值和方差,并对该区域做归一化处理,然后计算输出和目标局部归一化之后在VGG上的特征loss,目的是增强局部感受能力。基于GAN 的loss这里很有意思,采用的是成对图像的作为判别器的输入,即:
这么做的原因是,该数据集的输入和输出是非完全对齐的,这里成对的输入聚焦的是像素之间的相似性,关注输出与输入和目标与输入之间的相对的关系能否对应上,即相对的增强程度,同时提供更多的内容化信息。这个GAN使用的是relative GAN,比较的是相对概率,即:
此外还有内容相似性loss,即衡量VGG特征的统计相似性,表示如下:
其他部分不表,感觉主要还是这个pair GAN有点意思。