一篇期刊的论文,进行多任务图像增强。不同任务之间共享encoder,根据任务的不同,生成不同的语义图进行引导。整体结构图如下所示:
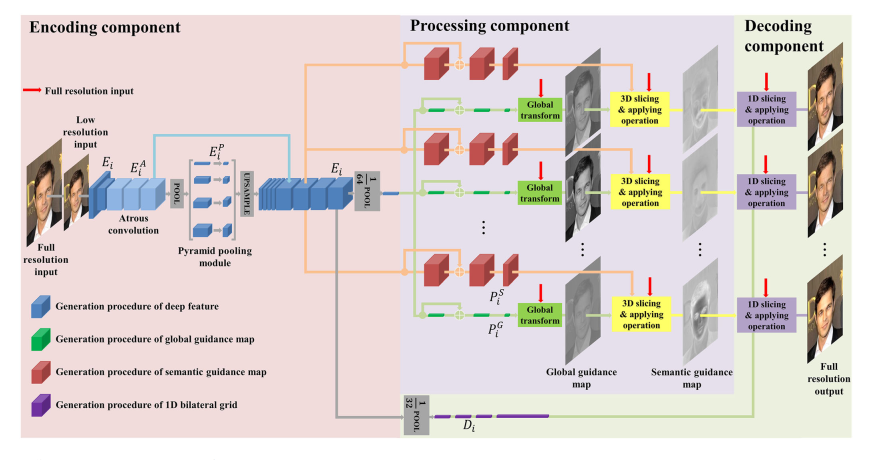
如上图所示,这里首先是一个encoder,将输入图进行下采样。然后估计语义引导图根据不同的操作算子。具体而言是先获得一个全局算子,对输入图做全局操作,获得全局引导图,语义引导图通过3D双边网格做局部操作获得。在decoder部分,这里使用语义引导图和1D双边网格去恢复图像。在这里1D双边网格对不同任务是相似的,可以共享,只有语义引导图是不同的。也就是说,整体结构里encoder和decoder是共享的,只有图像处理模块是不一样的。
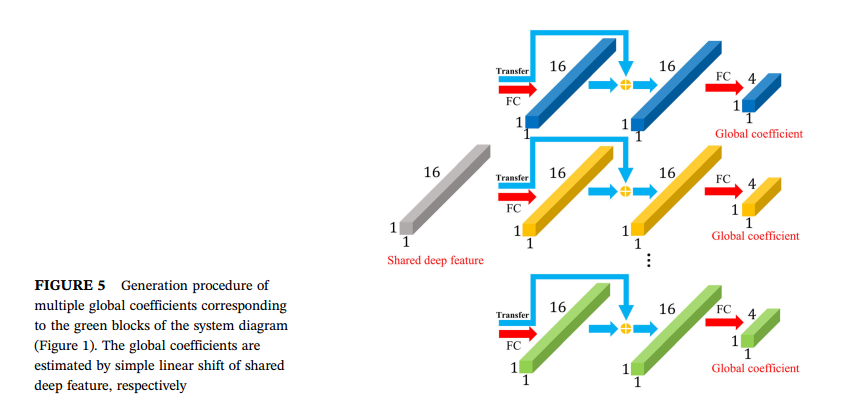
对于encoder模块来说,这里使用了空洞卷积获得大感受野,以及使用金字塔池化模块获得多尺度信息。这里最核心的操作还是图像处理模块。首先是进行全局的仿射变换,这里使用共享的encoder的deep feature,先进行fc,然后相加到原来的特征上,再fc成1x1x4的特征,获得全局变换系数。注意这里获得的全局和下面的仿射变换系数都是针对不同任务而不同的。如下图所示:
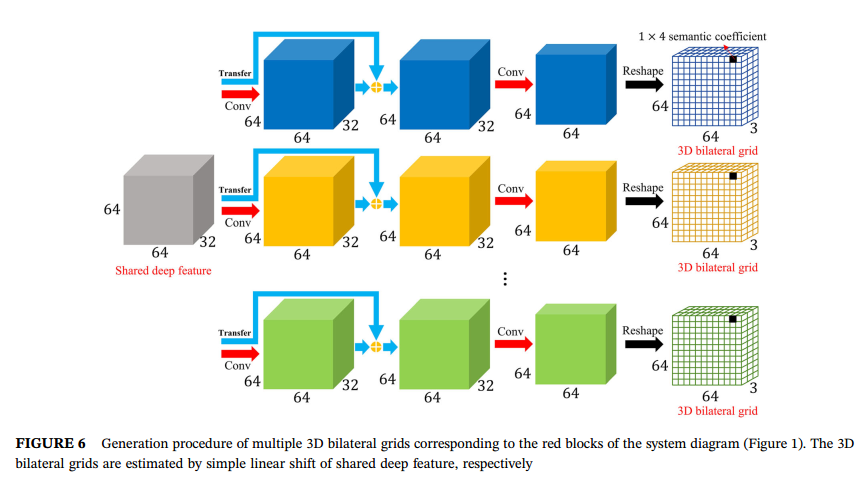
然后是获得3D双边网格的操作,这里使用先对encoder里64x64x32的特征做卷积操作,然后将其转换到12个通道,并且reshape成64x64x3x1x4,这样就变成了双边网格,每个成分的系数是4,如下图所示:
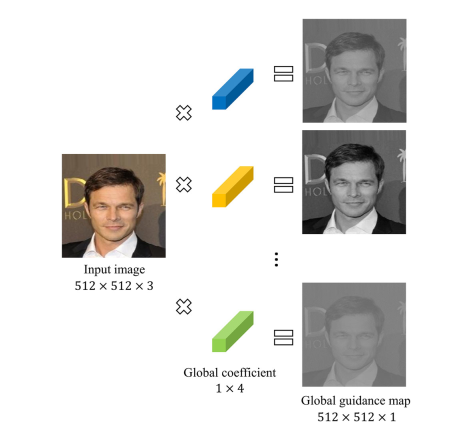
通过获得的不同全局系数,对输入图做全局的调整,这样可以根据不同任务获得不同的全局引导图,如下图所示:
然后是使用获得的双边网格对得到的全局引导图做操作,获得语义变换系数,再与输入图相乘,获得语义引导图,如下图所示:
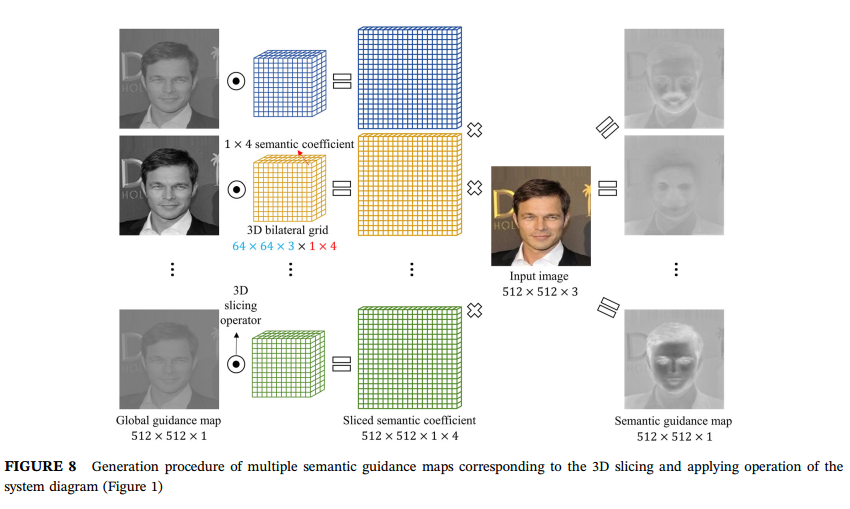
最后是encoder部分,这里对上面使用的语义引导图使用1D slice操作,获得3x4的slice仿射系数,作用在原图,得到最后的输出图像。因为语义引导图已经有了任务信息,所以这里1D放射变换的权重可以共享。如下图所示:
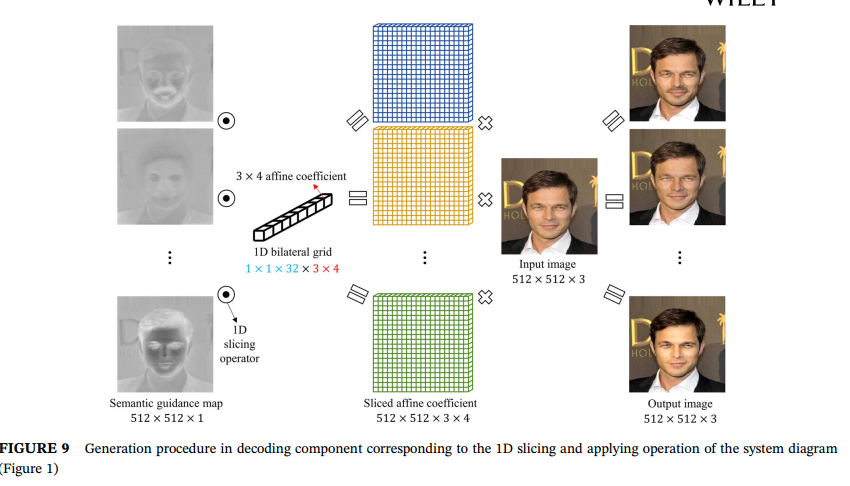
最后使用L2 loss进行训练。总之论文学习全局系数,语义引导图等还是有点意思的,但是具体实现可能有点难度。。。