好久没有写博客了,感觉后面写博客的时间越来越少了,毕竟精力有限。。。。这是刚刚在arxiv上挂出来的一篇论文,感觉有点意思。来看一下它主要在干些啥。。。
这篇论文提出的问题是如何对一张图像中低曝光区域进行增强,因为噪声多集中在图像中比较暗的区域,所以这里学习光照attention map对低曝光区域进行增强,同时去除这些区域的噪声。论文首先阐述其生成数据集的过程,简而言之就是通过gamma线性变换去降低图像曝光度,同时结合相机响应曲线利用高斯泊松混合模型生成噪声,具体见论文。整体结构图如下所示:
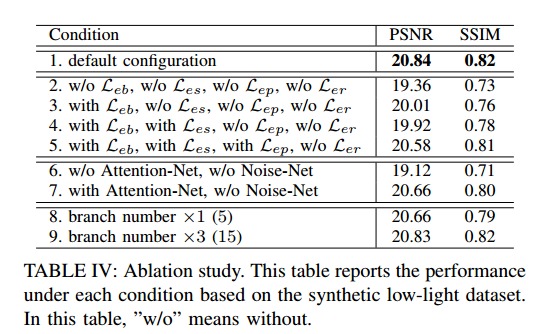
首先最左边的网络是学习光照attention map,其反映光照的相对亮暗程度。光照图的attention map由下面公式定义:
其中$\max_c$返回的是三个通道里最大的像素值,R是原始的图像,F(R)是合成的低光照图像。这样生成的A可以反映暗的程度,A的值越大表明该处相对越暗。这样最左边的网络目标就是学习这个A.
中间蓝色的这个网络是用来学习噪声分布,因为噪声分布和光照图非常相关,所以这里输入是光照attention map和输入图,生成噪声分布图。最后的右边是增强网络,采用的是多特征生成并联的方式,和MBLLEN使用相同的架构。最后加上一个增强网络做进一步的改善。
下面来看loss,loss对于上述四个网络分别进行。对于光照图attention map学习网络来说,这里使用的loss就是L2 loss,表示为$L_a = ||F_a(I)-A||^2$,同样的噪声分布图loss也是和生成的噪声之间的L1 loss,表示为$L_n = ||F_n(I,A’)-N||^1$。对于增强网络,这里的loss是一系列loss的组合,包括生成图和GT的L1 loss, SSIM loss, VGG loss, 以及区域 loss,这里来看一下这个区域loss,这个loss是使用了attention map进行不同区域加不同权重从而使得增强更加关注低曝光度的区域。这个loss表示为:
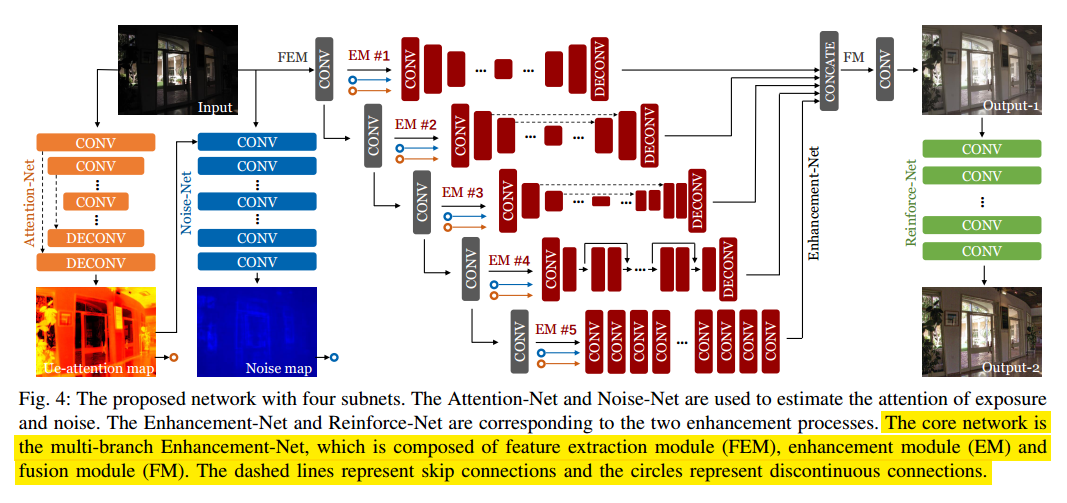
最后对于后面的继续增强网络,使用的是L1 loss,SSIM loss和VGG loss,训练是级联在一起进行训练。从论文给的结果上来看感觉还可以。这里就不赘述了。列一个表如下: