2019 ICCV去雨论文,基本思想是认为,一般的encoder对带雨图像的表征能力不够,更容易反映带雨的特征,很容易丧失其他属性例如纹理等。所以该论文的核心思路是引入另外一个encoder分支,对表征的特征做补充。基本原理图如下所示:
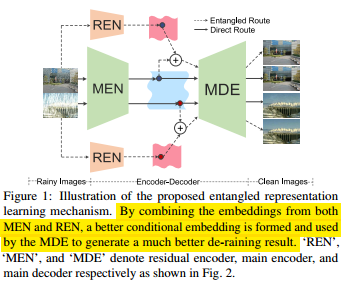
这里采用了如下两种结构去实现,具体不多说了,很容易看懂:

在loss上,这里使用L1 loss用来训练原始的encoder decoder网络,表示为:
加入引入的另一个encoder之后,需要增加一个新的loss:
这里第一项表示原始的encoder decoder网络里对应的encoder特征,第二项表示另一个添加的encoder对应的特征。最后一项表示clean-to-clean训练好的结果(encoder-decoder结构)在encoder对应的特征,也就是GT在encoder对应的特征,通过这个loss,可以约束另一个分支学习GT特征里的纹理等信息。
将上述两个loss做结合称为$L_{ERL-Net}$,这里有若干训练策略,如下表所示(其中MEN指代原来的encoder,MDE指代原来的decoder,REN指代添加的encoder):
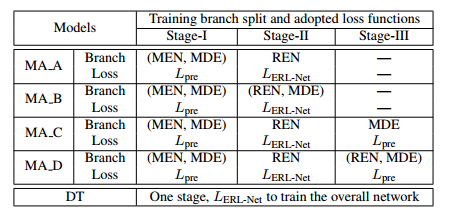
论文最后做了实验对这几种策略做了对比,详见论文。