2020 CVPR,使用生成模型实现人脸超分辨(其实没怎么看懂这篇论文,菜菜…..)。这篇论文没有去学习LR到HR的映射,而是采取了类似于自监督学习的方式去做,使得生成图像下采样后和LR图像更加接近。同时约束搜索空间,使得生成的高分辨图像更加真实。
首先论文提出基于MSE的LR-HR优化会导致输出图像高频区域模糊,而改进版本也没有很好的解决这个问题。一个示意图如下所示:
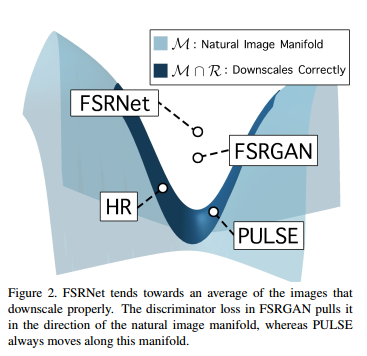
论文约束生成的SR图像通过两种约束,一个是无论生成的SR图像是什么样的,其down-sample之后要和LR图像保持一致性,通过下面的这个公式满足:
其次要保证生成的图像是自然的,通过GAN实现。这里对生成器输入的随机变量z进行约束,这里将原有的高斯先验替换成一个更强的先验,这个地方没看懂在干啥,示意图如下:
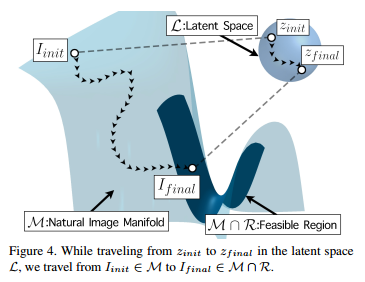
论文是在人脸超分辨这个领域做的,可能是因为人脸有更强的先验比较容易学习,效果还是比较惊艳的,图可以去看原论文。