2019 CVPR,感觉质量非常不错的一篇low level论文,在raw域上去解决超分辨问题。针对没有真实数据对的问题,这篇论文从raw域上去解决这个问题,对于以前方法里仿真噪声、降质与模糊核不够真实的问题,论文通过在raw域的线性空间进行合成降质后的训练数据,模拟相机成像过程(因为sGGB是各种线性与非线性处理后的结果,其在非线性空间上,在sRGB上合成降质是不如raw域上真实的)。另一个问题是以前的超分方法都是在sRGB上做的,没有利用raw域上的信息,使用raw有三个好处(bit数更高精度好;更方便学习在raw域里线性但是在sRGB里非线性的噪声和模糊;学习去马赛克)。此外,现有的raw to rgb方法直接学习raw到rgb的映射,但是raw数据里并没有颜色校正的相关参数,因此训练出来的网络只能适用于特定的相机,这里论文引入额外的参考color图,通过两个branch分别处理raw和RGB域参考图像分别实现细节恢复和颜色校正,从而使得训练的模型可以泛化到各种相机上(只要给定参考的RGB图)。整体流程如下所示:
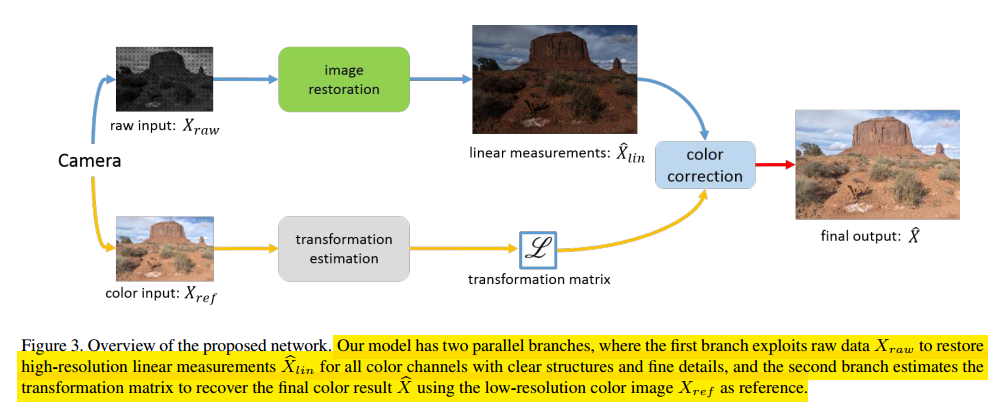
首先在合成数据时,这里首先合成GT的sRGB,主要操作是降采样和颜色校正。对于降质的输入图像,这里通过下面步骤实现:
两个f分别代表马赛克和降采样操作,两个k分别代表焦距模糊和运动模糊,n表示噪声,其分布为与像素值大小相关的高斯分别。参考图像$X_{ref}$生成方式和GT生成方式相同,这样两者的颜色也是一样的了。
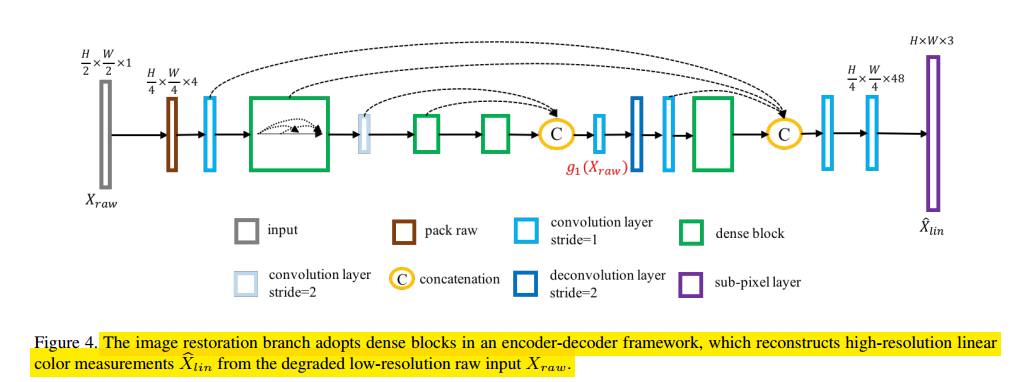
在网络结构上,这里采用两个分支分别处理raw和ref图。因为raw里没有颜色校正的信息,通过参考图也可以更好的学习这个过程,减少raw网络学习的负担。raw图像恢复网络如下所示:
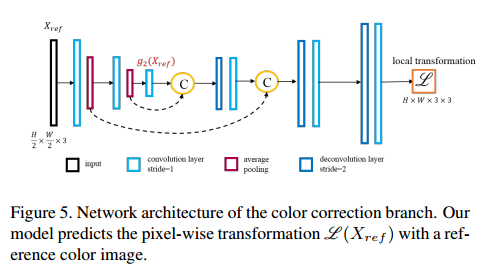
对于ref图处理分支,这里的目标是生成仿射变换图去校正raw图处理后的结果,这里仿射变换是在局部像素对RGB操作的,过程如下:
该部分网络如下:
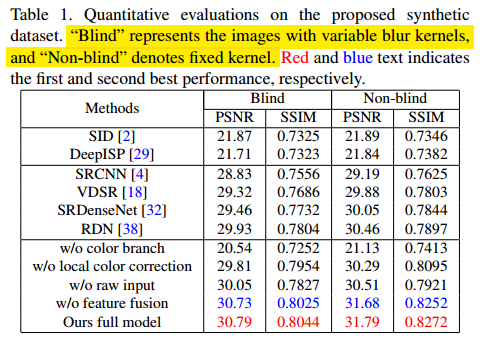
最后为了使得仿射变换图能够匹配上raw图处理后的结果,这里使用特征融合,将部分raw图分支的特征叠加在参考图分支上。最后,部分结果如下所示,可以看出论文提出的方法效果很好:
这篇论文个人感觉还是很好的一篇论文,一方面针对sRGB空间上非线性仿真降质不足进行改进,另一方面使用额外颜色校正学习减少整体网络学习难度和提高泛化性,值得多读几遍。