2020 cvpr,和2019 MM deep internal learning做背光图像增强那篇论文的出发点和idea都是一样的,相较那一篇在具体方法上也相似但稍微复杂一点。出发点仍然是使用没有GT的图像实现self增强,具体手段也是使用curve增强曲线。即通过对像素值增强方式和增强结果设置先验,利用网络模拟curve曲线进行引导与迭代增强。整体的framework如下所示:
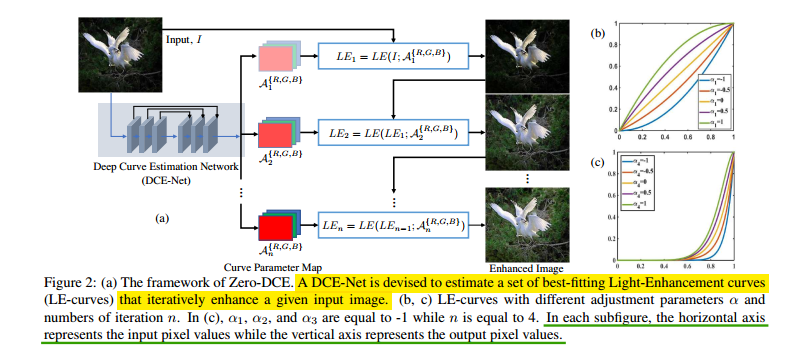
论文要求增强曲线要满足三个准则:1.增强后的像素值应该在【0,1】之间;2.增强曲线应该是单调的以确保相邻像素的相对大小关系;3.增强曲线应当是可导的以方便网络梯度回传。
这里迭代曲线使用如下所示:
注意,这里的曲线施加的对象是RGB每个通道分别施加的,这么做是为了保持颜色特性。上式x表示像素位置,n表示迭代次数,L表示像素值。因为全局映射没有考虑局部增强的差异性(例如过曝欠曝区域增强),所以这里的增强系数$\alpha_n$可以通过对局部区域的每个像素分别实行(即变成和像素位置x相关的函数),从而确保增强曲线的三个原则,上式即变为:
所以要使用网络生成这样pixel wise增强map A,网络是一堆卷积没啥特别的,最后生成24个map,分别用于8次迭代里生成的A。论文使用的一些loss如下,首先是Spatial Consistency Loss:

即局部区域和相邻区域的像素相对大小在增强前后不变,这里区域大小为4x4;然后是Exposure Control Loss,为了避免过曝或欠曝:
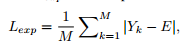
这里目的让局部区域的像素平均值尽可能接近E(设为0.6),局部区域大小是16x16;然后是Color Constancy Loss,如下如下所示:
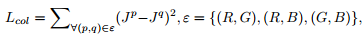
这里是要让增强后的颜色尽可能相关,最后是Illumination Smoothness Loss,目的是为了让光照图也就是A保持单调性,同时也符合光照图的平滑先验:

将这几个loss联合在一起训练。论文使用的数据集是SICE数据集,输入是part1,参考的GT是Part4。没有使用LOL和SID数据集猜测是因为此论文没有考虑噪声的因素(这个地方有灌水新空间嘿嘿),具体实验结果参考论文,此处不表。