CVPR 2020,还是基于coarse to fine的思路,motivation是,对于低光图像恢复,其noise在低频区域更容易被捕获和消除,因此先对低频区域做处理可以更好的保留足够的颜色等信息,再基于恢复的低频对高频进行处理恢复细节,根据低频恢复高频这样也更加容易一些。因此,论文提出了一个ACE模块用来分离低频和高频区域的信息(当然中间是加了低频监督实现的,单纯的这个模块肯定是不行的),先实现噪声去除和低频信息恢复。使用CDT模块辅助实现多尺度的噪声去除和细节恢复,论文提出的整体模型如下所示:
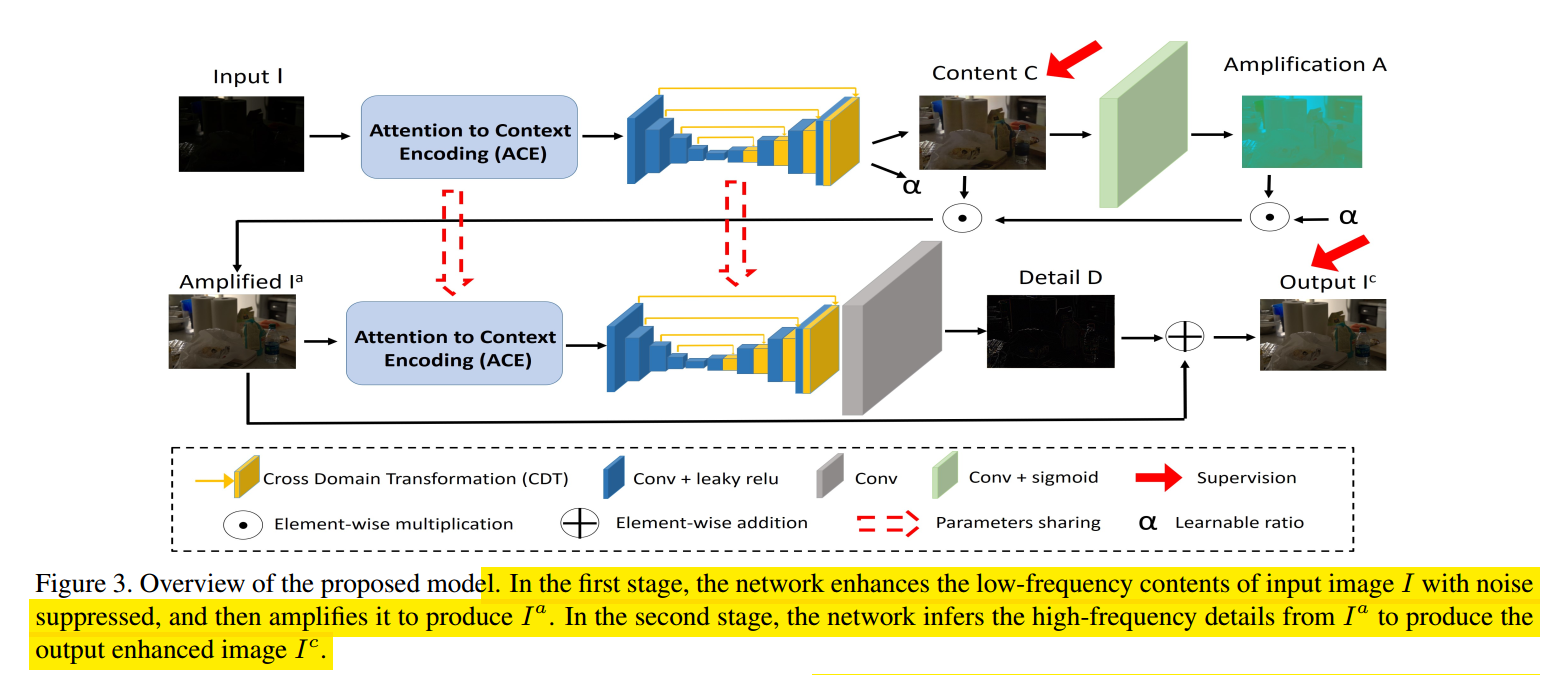
如上图所示,这里首先是获得一个content map C,然后通过C得到一个放大图A,借助A对C进行进一步的增强,这里并非retinex的那种illumination map的增强,而是类似于一种attention,过程表示如下:
其中$\alpha$是一个全局增强系数,也是通过C获得的。第二步细节恢复输入是第一步的结果,该过程通过一个残差的方式实现。
ACE模块是为了得到图像的高低频信息,如下所示:
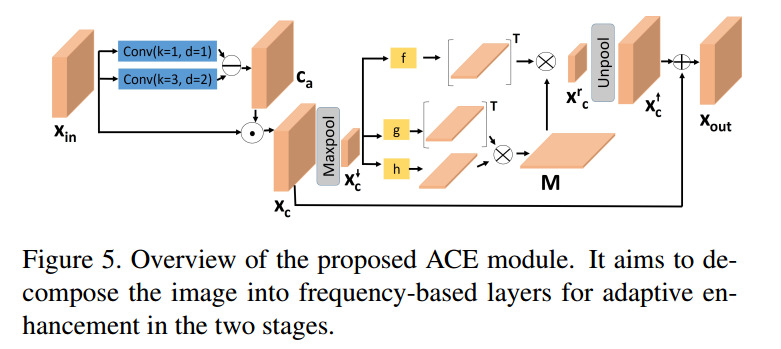
如上图所示,这里通过两个不同dilated的卷积feature相减,得到一个contrast map $C_a$,然后用1-$C_a$去表示低频区域,记为$\hat{C_a}$,再用这个低频map乘以输入,得到图像的低频部分,最后通过一个nonlocal模块,实现非局部式的增强(这儿做降采样实现减小计算量),这里在第一个图中的两个ACE是共享权重的。
对于CDT模块是为了减小输入特征和增强特征的domain并扩大感受野,如下图所示:
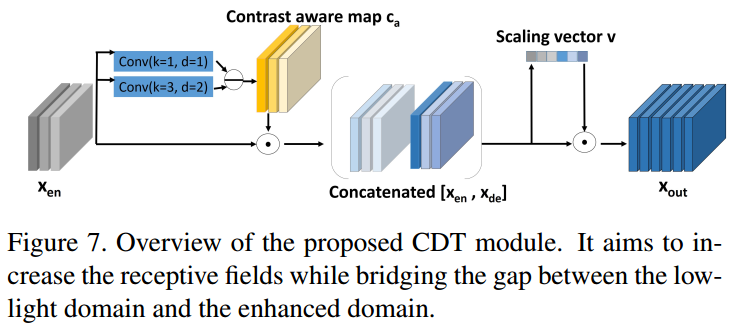
如上图所示,第一个阶段这里也是使用$\hat{C_a}$作为引导滤出高频区域,然后使用self attention生产vector进行channel 放缩,第二个阶段同理,不赘述。在loss上,这里对第一个阶段使用gt的低频区域作为监督,第二个阶段使用GT本身作为监督,如下所示:
四项分别是第一个阶段的content图,GT的低频图,最终的增强图和GT图。此外,论文还使用了VGG loss。
总而言之,论文使用了coarse to fine的思想实现增强,但是感觉对比的方法不够新,且参数量和速度上也没有对比,不知道相同条件下和其他比较新的方法对比效果如何。