2020 Arxiv的一篇论文,基本思想是添加更模糊的图像实现更好的去模糊效果,更模糊的图像可以在训练中学习得到。
之前方法的问题
之前方法和论文方法对比如下图所示:
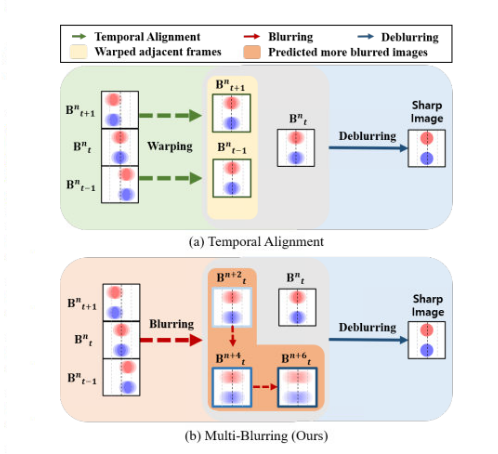
1.使用temporal align的方法过于粗暴,容易产生较大计算量与artifacts
2.基于循环网络的方式效果不足够好
论文提出的点
1.加入额外的模糊图像可以提升去模糊的性能,这里所受的启发是传统方法里的非锐化掩膜思想,高频信息可以通过更模糊的图像获得
2.使用RNN方案MBRNN生成更模糊图像,借助相邻帧生成
3.去模糊网络使用多尺度方法,结合MBRNN的特征,从而使得生成模糊和去模糊的步骤能更好结合在一起
论文的方法
论文提出方法的框架如下所示:
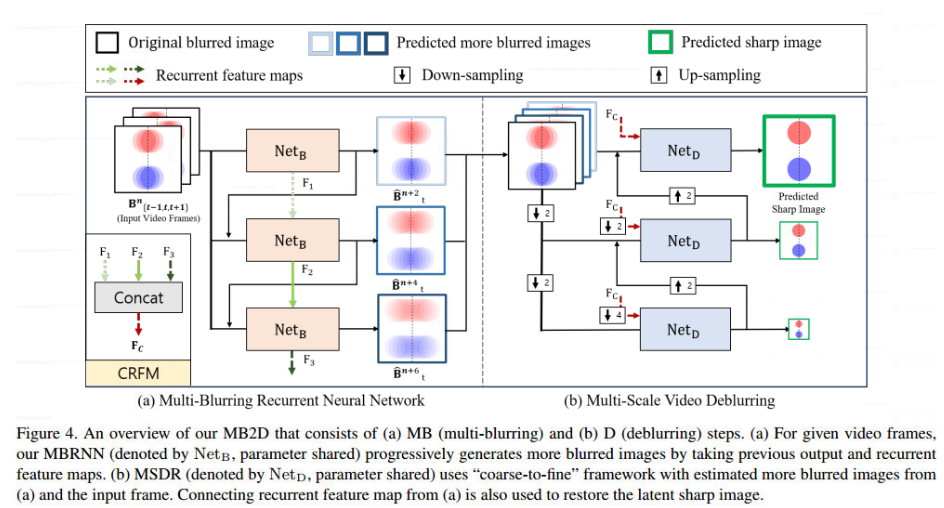
1.对生成模糊的网络MBRNN,这里输入之前迭代生成的模糊图像,原始的多帧图像和之前迭代的特征在encoder和decoder相连,如上图a所示
2.对于去模糊网络,这里使用多尺度框架,输入是前一次迭代恢复的结果,生成的更模糊图像和输入的当前帧图像,注意,这里没有使用其他帧图像作为输入,因此没有对齐这个过程,这里还是有点东西在里面的
3.去模糊网络还输入之前MBRNN的多次迭代的特征,这里将他们concat在一起然后送入,可以有效充分利用模糊边缘等信息
结果与思考
看上去效果还可以,见论文
思考:和上一篇multi temporal思路很像,只是这里是对模糊进行了再生成,从而隐式的利用的多帧信息,避免了对齐的过程,对于多帧图像处理类任务有参考与借鉴意义。