RefineNet
这个网络主要针对使用膨胀卷积在不进行下采样扩大感受野出现的限制(限制高层特征和输出尺度只能为输入的1/8,膨胀卷积导致严重的细节损失),以及FCN8-s不能有效利用中间层信息。这里认为所有层的信息对于语义分割都是有帮助的。高层的信息识别图像的区域类别,底层有利于保留轮廓、细节等信息。RefineNet结合这些特征进行设计。
网络结构如下所示,这里主要是将不同分辨率的特征图进行融合,最左边一栏使用的是ResNet,即将图像通过预训练好的ResNet获得特征图(这个ResNet按特征图的分辨率分成四个ResNet blocks,不同的block输出不同分辨率的特征图,这样就有高层和低层特征之分),然后向右把四个blocks分别作为4个path通过RefineNet block进行融合,最后获得一个refined特征图。除了RefineNet-4,所有的RefineNet block 都是二输入的,用于融合不同level做refine。
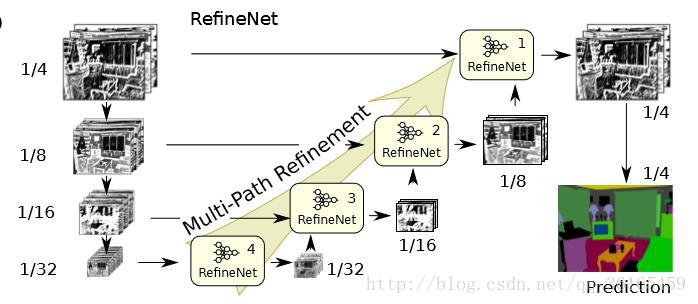
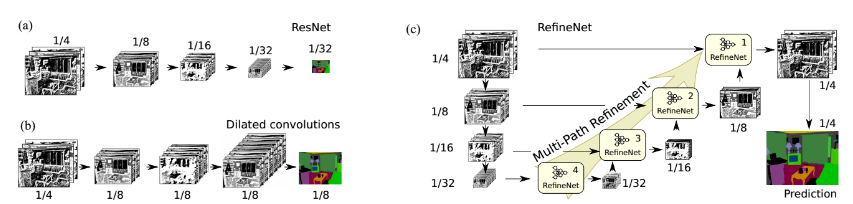
RefineNet和之前分割网络的对比如下所示,可以看出其融合了各层的信息:
具体的block如下图所示:
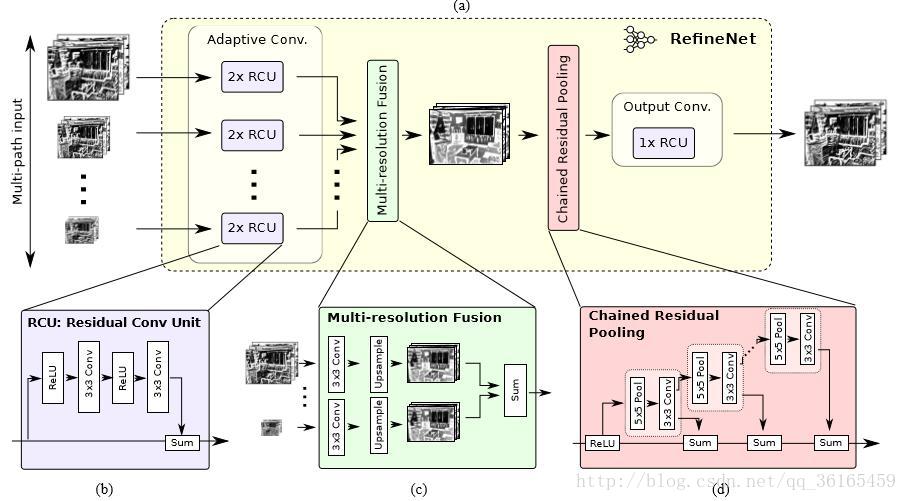
其中各部分分别是,RCU:从残差网络中提取出来的单元结构;Multi-resolution fusion:将特征图用一个卷积层自适应卷积成一样大小,再上采样,做element-wise 的相加,第一个Refine Block除外。Chained residual pooling:这里使用链式结构很容易获得背景的context,且使用大量的identity mapping这样的连接允许梯度直接传播,池化也使得模型对于学习率的变化不是那么敏感;Output convolutions:输出前再加一个RCU。
这个网络充分融合了各层特征和上下文信息,思路值得借鉴。
PSPNet
这个网络和上一个网络的思路不太一样,主要是考虑不同感受野下的全局信息,因此使用了金字塔池化的方法。网络结构图如下所示:

对于输入图像,这里首先通过ResNet网络获得特征图,这个特征图通过一个全局平均池化层之后,又通过金字塔池化层获得不同子区域的特征,然后上采样并和前面的全局特征concat在一起,这样的特征就包括了全局特征和局部特征,最后将输出通过一个卷积得到预测结果。
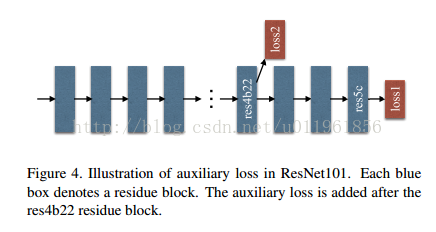
这里值得一提的是对于resnet网络的训练,除了使用softmax loss,即图4中loss1训练最后的主分类器外,还引入了res4b22 residule模块,构造另一个辅助分类器,损失函数为loss2,并引入一个权重参数来控制loss2的权重,辅助分类器可以帮助优化学习过程。如下图所示:
参考:
1.https://blog.csdn.net/qq_36165459/article/details/78345269
2.https://blog.csdn.net/u010067397/article/details/78836173
3.https://blog.csdn.net/u011961856/article/details/77165427
4.https://blog.csdn.net/yxq5997/article/details/53695779?utm_source=itdadao&utm_medium=referral