deeplab-v3
在看deeplab-v3之间简要了解一下deeplab-v1和deeplab-v2网络。deeplab-v1网络主要是在保持feature map不变小的情况下,尽可能的增大感受野,这里采用了空洞卷积的方法,最后加上全连接的条件随机场进行优化。
deeplab-v2主要是参考了多尺度在深度学习里的优点,设计了不同的空洞卷积核,从而获得不同的感受野,如下图所示:
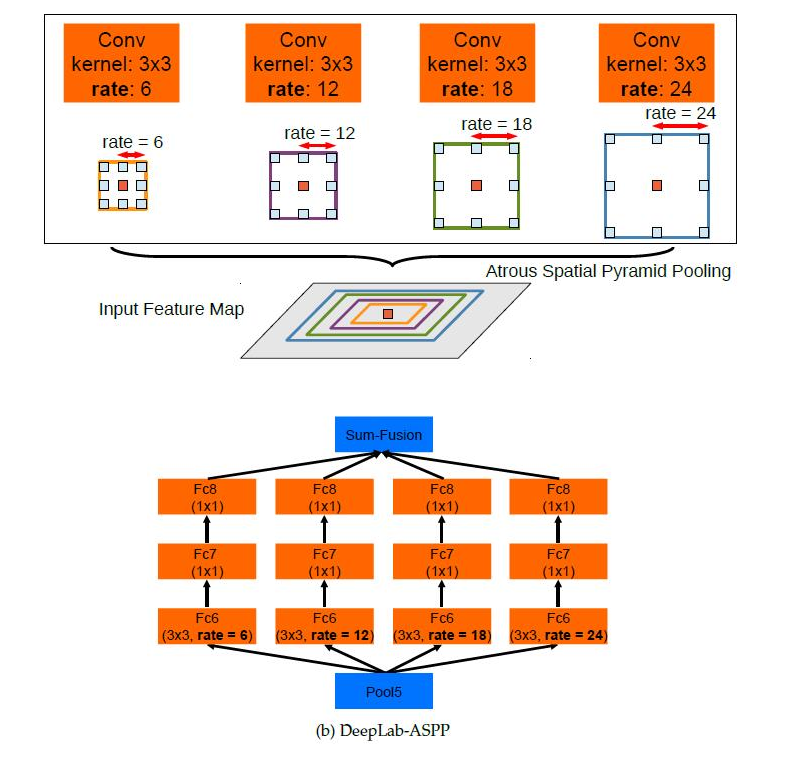
deeplab-v3网络做了进一步的改进,主要包括:
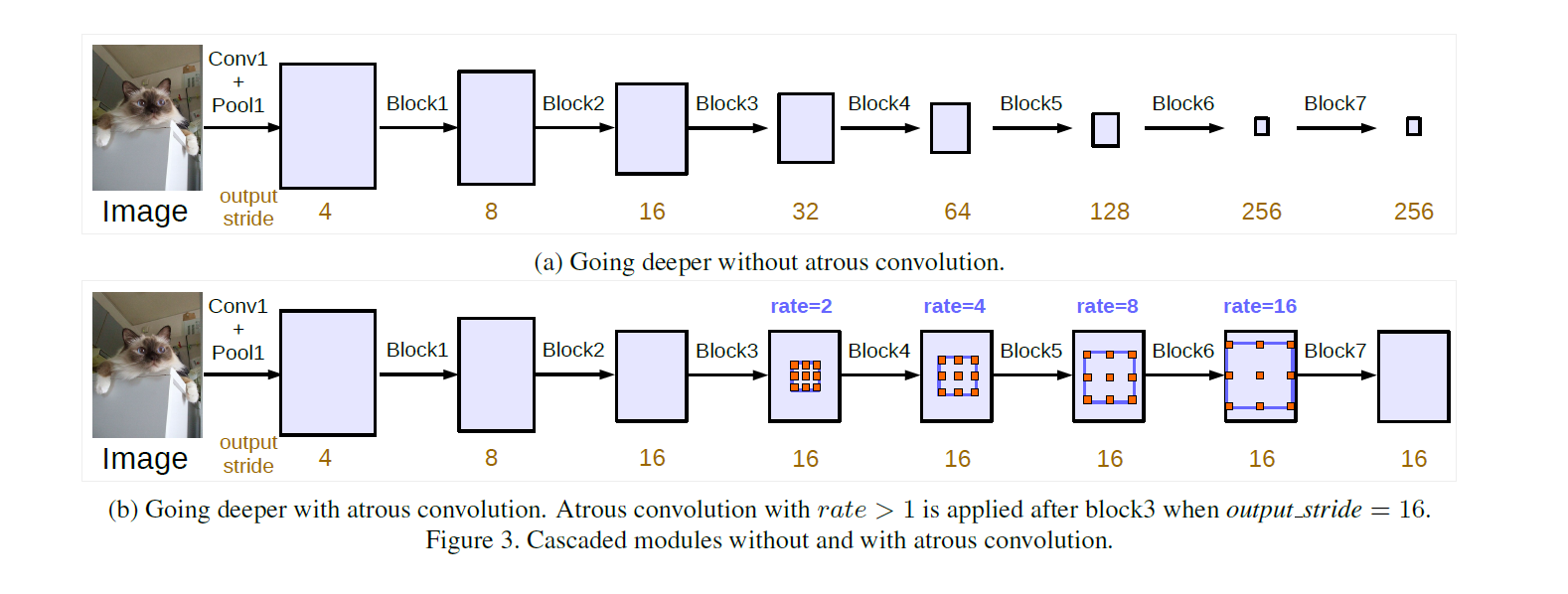
1.使用深层次的空洞卷积
一般的ResNet卷积到最后feature的大小会非常小,这会损失大量的信息,这里将下面ResNet里的block4拿出来,做多次复制接在后面,使用空洞卷积提取后面的信息扩大感受野,卷积中采用不同的采样率保持out_stride = 16,从而减少了计算量。如下图所示:
2.使用多尺度空洞卷积,和v2差不多,相当于将上面的部分空洞卷积在原有基础上乘上不同的rate,建立多个分支。此外,还加入了BN层。
3.空洞金字塔池化
具有不同采样率的上述模块在卷积时可以获得多尺度信息,但是论文也发现,在采样率增加时卷积核里有效的权重数会减少,也就是说在采样接近特征图大小的极端情况下,3x3的卷积会退化成1x1的卷积,只有中间的权重发挥作用,如下图所示:
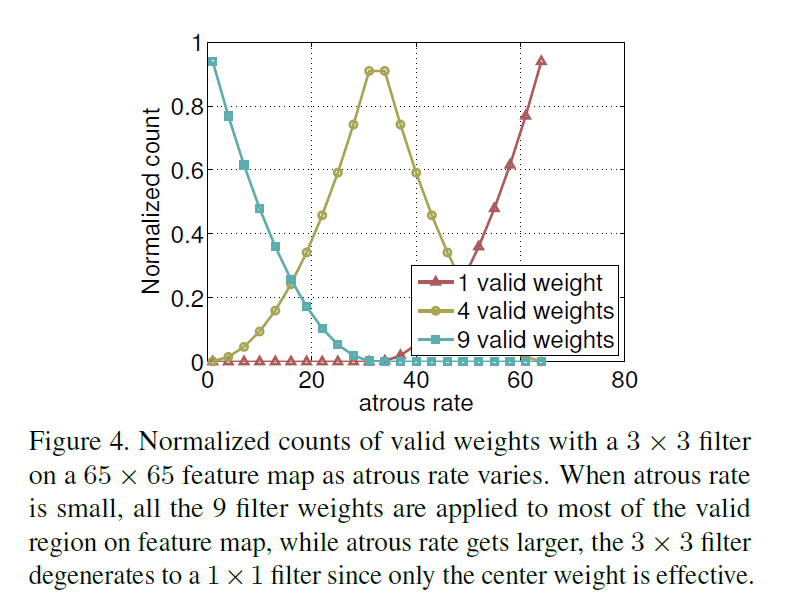
为了解决这个问题,这里采样图片级特征,在模型最后的特征映射上应用全局平均,将结果经过1×1的卷积,卷积核为256个,再双线性上采样得到所需的空间维度。所以ASPP包括:1.一个1×1卷积和三个3×3的采样率为rates={6,12,18}的空洞卷积,滤波器数量为256,包含BN层。针对output_stride=16的情况。如下图(a)部分Atrous Spatial Pyramid Pooling。2.图像级特征,即将特征做全局平均池化,经过卷积,再融合。如下图(b)部分Image Pooling。如下图所示:
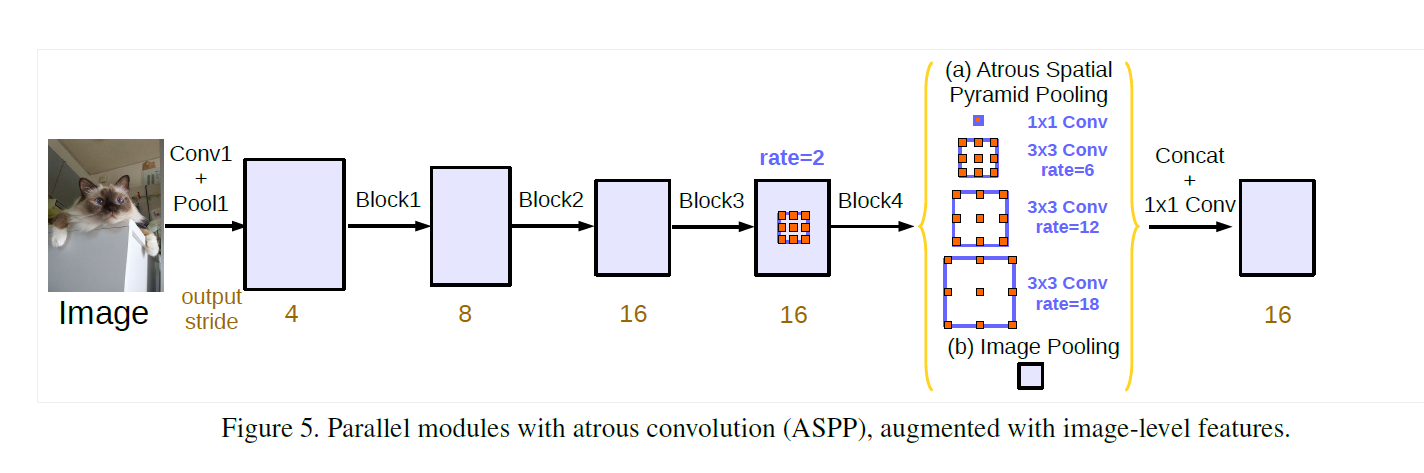
与deeplab-v3+
deeplab-v3对输出直接做上采样恢复到原来的尺寸大小,这会损失大量的细节信息。所以这里引入了decoder部分希望能较好的恢复细节信息,具体操作是encoder部分继续使用deeplab-v3,对于decoder部分:
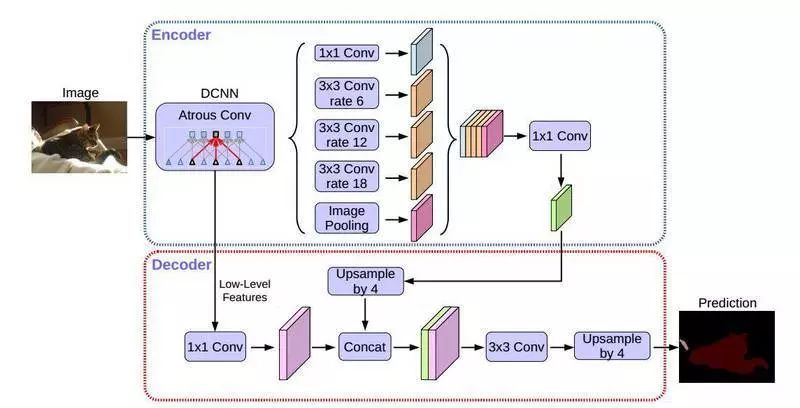
先使用1x1卷积将低层特征进行通道压缩,再和上采样后的通道进行concat,前面的低层特征相当于是一个权重,从而保留高级特征的同时,也引入了低层的细节和边缘等信息。
参考:
1.https://blog.csdn.net/u011974639/article/details/79134409
2.https://blog.csdn.net/caicai2526/article/details/79984950
3.https://blog.csdn.net/u011974639/article/details/79144773
4.https://blog.csdn.net/JYZhang_CVML/article/details/79594940