这是2017 siggraph的一篇论文,寒假boss让我看这篇论文我没怎么看懂。最近在公司实习,发现该论文的成果已经移到手机端上了,效果还非常不错。这里我重新温习了一下这篇论文,发现有许多可以借鉴的地方,是一篇非常不错的论文,这里重新叙述一下,谈谈我的理解。
首先说一下这篇文章的整体思路,这篇文章对于图像增强的方法是,将图像首先做下采样,继续卷积下采样几次然后分别学习其全局特征和局部特征,并且结合之后再将其转换到双边网格之中。此外,对输入图像做仿射变换得到引导图,并将其用来引导前面的双边网格做空间和颜色深度上的插值,恢复到和原来图像一样大小。最后将得到的这个feature对原图像做仿射变换,得到输出图像。也就是说,整个过程就是再学习最后的那个变换矩阵。整体架构图如下所示:
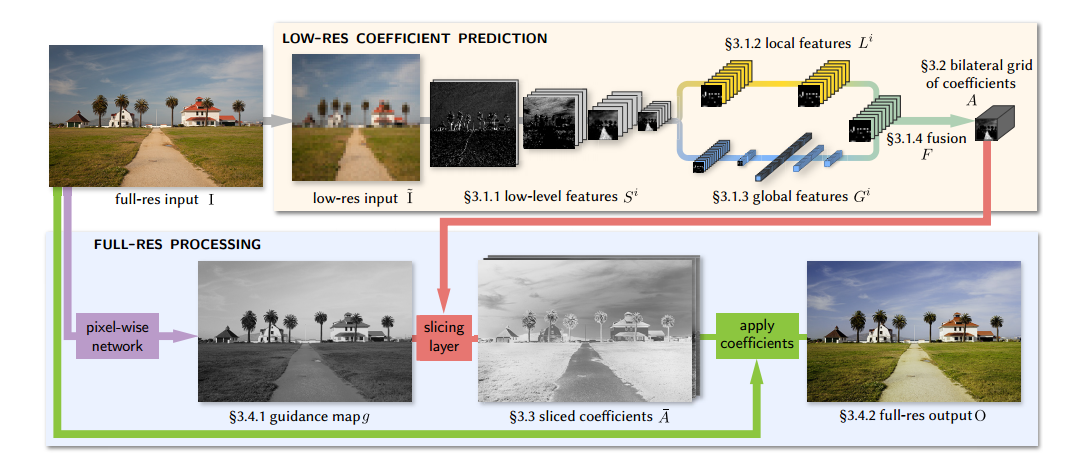
在Introduction里,论文提出了其三个策略,分别是:
- 将大部分的预测在低分辨的双边网格下进行,每个像素包括的x,y维和第三维可以表示颜色功能,可以用来在对3D双边网格做slicing操作的时候考虑到输入的颜色。
- 学习输入到输出的变换过程,而不是直接学习输出,因此整个结构学习的是一个仿射变换。
- 虽然大部分的操作是在低分辨下进行的,但是损失函数最终建立在原来的分辨率上,从而使得低分辨下的操作去优化原分辨下的图像。
这篇文章主要是在先前的基础上进一步改进的,包括联合双边上采样(JBU),这里是通过将双边滤波器作用在高分辨的引导图去产生局部平滑但是也保留边缘的上采样;双边引导上采样(BGU)则是引入了在双边网格里进行局部仿射变换,再通过引导图进行上采样。这篇论文实际上就是将BGU里的仿射变换操作通过网络进行学习。
进入正题,网络主要学习低分辨率下的仿射变换。图像增强不仅与图像局部特征有关,和图像的整体特征也有关例如直方图、平均亮度和场景类别(其实这里它就是想消除artifacts,不加global消除不了)。因此这里低分辨流的部分分成了局部特征和全局特征两个路径,最后融合成一个特征用来代表仿射变换。而对于高分辨流,这里主要的任务是在尽可能减少计算量的前提下,保留更多所需的高频部分和边缘信息,这里引入了双边网格里的slicing节点,该节点在引导图的基础上,在低分辨率网格的仿射系数中执行与数据相关的查找,从而实现上采样恢复到和原分辨率一样大的变换,最后作用在每个像素上并输出作用后的结果。
低分辨的特征提取
1.Low-level 特征
这部分没什么好说的,就是对图像进行下采样,通过一系列stride=2的卷积来实现(实际操作是先将图像resize成256x256再做这个特征下采样的),公式如下:
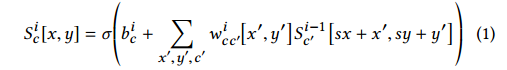
上式中,式中,I=1,…,$n_S$为每个卷积层的索引,c,c′为为卷积层的channels的索引.w′为卷积核权重矩阵,$b^i$为bias.激活函数σ采用ReLU,卷积时采用zero-padding。
从这里可以看出,图像实际上是缩小了$2^{n_S}$倍,这个$n_S$有两个作用,1.其驱动学习低分辨输入和最后网格里仿射系数的学习,$n_S$越大,网格就越粗糙;2.其控制预测结果的复杂度,更深的网络层数可以获得更复杂更抽象的特征。这里论文设定$n_S$为4,卷积核大小是3x3。使用这个特征提取可以增强模型的表现力,如下图所示(和去除这部分使用a hard-coded splatting operation对比):

2.局部特征
上部分特征进行进一步处理,通过$n_L=2$的卷积层进一步提取特征,这里设定stride=1,也就是这部分分辨率不再改变,同时通道数也不发生改变。所以加上前面的Low-Lebel那里用到的卷积的话,总共是$n_L+n_S$层卷积,如果需要提高最后网格系数的分辨率,可以通过减少$n_S$同时增加$n_L$来实现,这样总层数不变,网络的表现力也不会变化。如果没有局部特征,预测出来的系数会失去空间的位置信息。
3.全局特征
全局特征也是对Low-Level的特征进行进一步的发展,这里让$G^0:=S^{n_S}$。它包括两个stride=2的卷积层,再接着三个fc层,所以这里的全局特征一共有$n_G=5$层,当然这个fc层要求feature的大小是固定的,网络的输入图在提取特征时已经Resize成256x256了,所以这里不用考虑这个问题。
全局特征具有的全局信息可以作为局部特征提取的先验,如果没有全局特征去描述图像信息的高维表示,网络可能会做出错误的局部特征表示,从而出现如下图的artifact:

4.融合和线性预测
这里使用一个逐点的放射变换去融合全局特征和局部特征,使用relu函数进行激活,这里其实就是仿射相加,如下式所示:
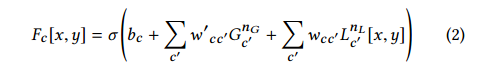
这样得到了一个16×16×64的特征矩阵,将其输入1×1的卷积层得到16×16大小,输出通道是96的特征:
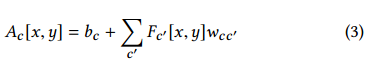
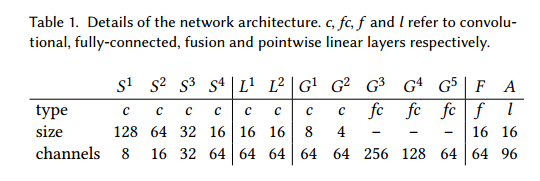
网络的参数图如下所示:
将特征作为双边网格
上述得到的融合特征可以作为第三维已经展开的双边网格:
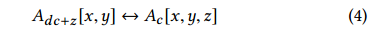
这里d=8,也就是网格的深度,通过这个转换,A可以看做是一个16x16x8的双边网格,每个格子有一个3x4的仿射颜色变换矩阵。这个转换使得前面的特征提取和操作都是在双边域中操作的,其对应于在x,y维上进行卷积,学习z和c维相互交融的特征。因此前面提取特征的操作也比使用3D卷积在双边网格中卷积更具有表现力,因为后者只能关联z维。同时其也比一般的双边网格要有效,因为其只关注c维上离散化。总之,也就是通过利用2D卷积并将最后一层作为双边网格,可以用来决定2D转换到3D的最优方式。
使用可训练的slicing layer进行上采样
这一步是要将上一步的信息转换到输入的高分辨率空间,这步操作基于双边网格里的slicing操作,通过一个单通道的引导图将A进行上采样。利用引导图g对A进行上采样,是利用A的系数进行三次线性插值,位置由g决定:
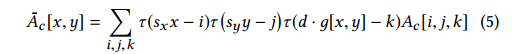
这里的$\tau(.)=max(1-|.|,0)$表示线性插值,$s_x$和$s_y$分别表示网格和全分辨原图的高度和宽度比例,特别的,每个像素都被分配了一个系数(这个系数应该是上面仿射变换的系数),其在网格里对应的深度由图像灰度值g(x,y)决定,也就是$A_c[i,j,g[x,y]]$。这部分有点难理解,个人理解是使用引导图对网格进行插值,插值后每个像素的深度是对应的引导图像素xd减去对应网格的深度(虽然这个深度是一个3x4的仿射变换,个人理解是对这个3x4矩阵的每个元素都做相同的操作,得到的也是一个3x4的大图)。这里的slicing使用OpenGL库完成,通过这个操作使得输出图的边缘遵循输入图的边缘,达到保边的效果,这个效应相对于反卷积来说更加明显,如下图所示。通过这个操作,可以将全分辨下复杂的操作转换成许多简单的局部操作(也就是在每个网格对应图像的操作)。

实现全分辨的最终输出
后面的操作都是在全分辨率下进行的了,对于输入图像I,提取其特征$\phi$实现两个作用:1,它们可以用来获得引导图g;2,可以用来给上述得到的全分辨局部仿射模型做回归。
1.获得引导图的辅助网络
这里将引导图的获得通过下面的公式,也就是对原始图像三个通道操作后相加得到:
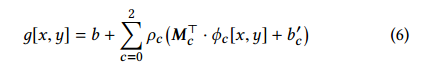
其中$Mc^T$是一个3x3的颜色转换矩阵,b和b’是偏置,以及$\rho_c$是一个分段线性的转换模块,包括阈值$t{c,i}$和梯度$a_{c,i}$,由16个relu激活的单元相加得到:
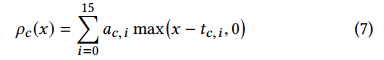
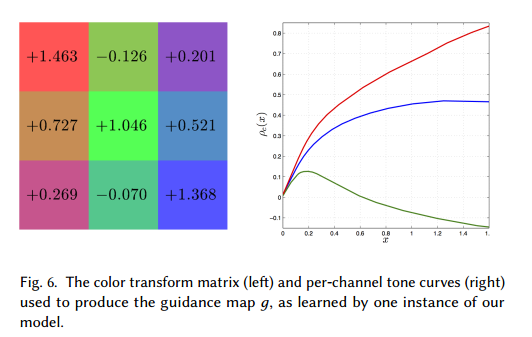
这里的参数$M$,a,t,b,b’都是通过学习获得的,值得一提是是$\rho$限定在[0,1]之间去避免学习到一个退化的引导图。下面的两个图分别表示颜色转换矩阵,以及使用学习得到的引导图的效果:

2.获得最终的输出
最后的输出可以看做是对输入特征做仿射变换后的结果,如下式:
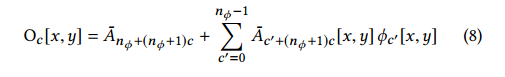
这里还对仿射变换时patch大小(这里个人理解是每个网格对应的像素范围)的尺寸做了讨论,尺寸较小时,效果也越好,但是速度较慢;尺寸较大时则正好相反。3D双边网格可视化的结果如下,其中纵轴是深度d=8,目的是进行颜色采样,横轴是仿射变换对应的值,如下图所示:

其他
对比实验及结果这里不再写了,这里简要说一下其限制。
1.可以通过对输入图做特征进一步的提取特征来增强其表达效果。例如一个网格里使用36个仿射变换系数作用在一个层级为3的高斯金字塔处理的输入图要比原始的bilateral效果更好,尽管速度会变慢,如下图所示:

2.将该网络用在增强外的其他任务上,如色彩化、去雾、深度估计等效果较差,这是因为其有较强的假设即输出是由输入的局部仿射变换得到的。
参考:
https://blog.csdn.net/u011961856/article/details/77427977