在深度学习项目里常常用到一些梯度学习算法,最常见的我们使用的SGD,Adagrad,Adam,RMSProp和momentum,这里参考网上别人写的教程简要理解一下这些梯度下降算法。
SGD
说SGD,就必须先说一下批量梯度下降BGD,其训练的是整个训练集的梯度,即:
其中$\eta$是学习率,下同,用来控制更新参数的力度。优点是对于凸目标函数,其可以保证全局最优,对于非凸目标函数,可以保证一个局部最优。但是存在一个明显的缺点,就是在数据量较大时更新会非常慢,无法处理动态产生的新样本,在这种情况下,就需要考虑SGD。一般的SGD只利用单独的数据,虽然优化速度快,但是可能会导致收敛更复杂,出现更多的动荡。所以我们一般使用的SGD实际上是MSGD。
MSGD不同于原始的SGD只利用单个数据,这个梯度下降算法是将整个数据分成n个batch,每个batch分成m个样本,每次更新参数利用一个batch的数据(xi,yi)而不是整个训练集的数据,其更新参数如下所示:
通过这种批量的梯度下降,减少了原始SGD参数更新中的动荡;同时利用先进深度学习库中常见的高度优化矩阵操作来高效地计算小批量的梯度。
当然MSGD也存在许多困难,主要表现如下:
1.学习率选择较为困难,太小的学习率收敛太慢,过大的学习率会偏离最优点。
2.目前可采用的方法是在训练过程中调整学习率大小,例如模拟退火算法:预先定义一个迭代次数m,每执行完m次训练便减小学习率,或者当损失值低于一个阈值时减小学习率。然而迭代次数和阈值必须事先定义,因此无法适应数据集的特点。
3.一般情况下神经网络面临的是非凸的优化函数,这也意味着优化容易陷入到局部最优,也就是陷入到马鞍面中,即在坡面上,一部分点是上升的,一部分点是下降的。而这种情况比较容易出现在平坦区域,在这种区域中,所有方向的梯度值都几乎是0,此时SGD很难发挥作用。
介于此,可以使用一些优化算法对SGD做进一步的优化,常见的有;
Momentum
SGD的问题是其依赖于当前batch的梯度,因此导致下降不稳定,出现来回波动的情况,如下图所示:
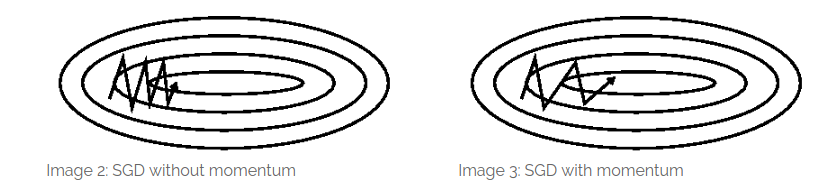
所以引入动量的方式,加速SGD的优化过程,它模拟的是物体运动时的惯性,在更新梯度时上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
根据上式,可以更直观理解动量的含义,当前梯度和上次梯度加权,当方向一致时,累加导致更新步长变大;如果方向不同,则相互抵消导致更新趋向于平衡。
Adagrad
Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。Adagrad为每个参数$\theta_i$提供一个和自身相关的学习率:
其中$G_t$是对角矩阵,每个对角线位置i,i为对应的参数$\theta_i$从第一轮到第t轮的平方和,$\epsilon$是平滑项,防止除0。通过该式,还可以看出,随着训练次数的增加,分母变大,学习率会自动下降。但是训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
RMSprop
RMSprop是Geoff Hinton提出的一种自适应学习率方法。Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题。下面的$g{t,i}$表示$\nabla{\theta}J(\theta_{t,i})$
Adam
Adam(Adaptive Moment Estimation)是另一种自适应学习率的方法。与RMSprop相比,其在梯度平方估计(二阶矩)的基础上增加了对梯度(一阶矩)的估计,Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式表达如下:
上式中$m_t$,$v_t$分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望$E[g_t]$,$E[g^2_t]$的近似;$m’_t$,$v’_t$是对$m_t$,$v_t$的校正,这样可以近似为对期望的无偏估计。在数据比较稀疏的时候,adaptive的方法能得到更好的效果,例如Adagrad,RMSprop, Adam 等。Adam 方法也会比 RMSprop方法收敛的结果要好一些, 所以在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果。
参考:
1.https://blog.csdn.net/liujiandu101/article/details/55190814
2.https://blog.csdn.net/sxf1061926959/article/details/74453600
3.http://lib.csdn.net/article/deeplearning/47027
4.https://www.cnblogs.com/darkknightzh/p/5785137.html
5.http://ruder.io/optimizing-gradient-descent/index.html