最近阅读CVPR2018和自己所做方向相关的论文,这里限于时间就简要介绍一下这些论文的主要思想。
Fast and Accurate Single Image Super-Resolution via Information Distillation Network
这篇论文是做快速超分辨用的。网络的主体和VDSR一样,是学习输入和目标的残差部分,包括增强模块,压缩模块和特征提取模块,网络的结构图如下所示:
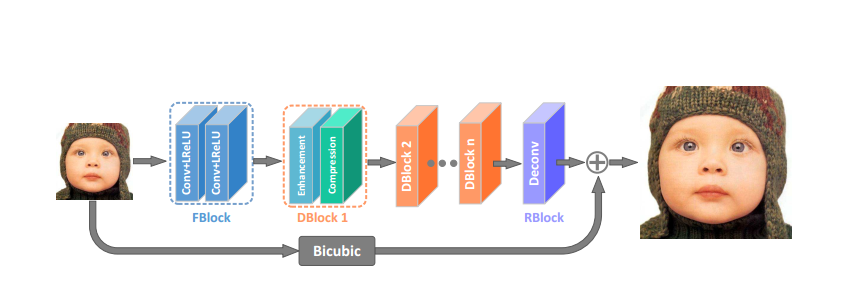
特征提取模块就是上图的FBlock,就是一般的CNN模块,然后网络的重点是图中所示的DBlock,包括一个增强单元和压缩单元。增强单元如下图所示:
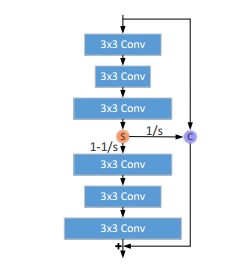
增强模块里,让$D_i$表示自上而下的第i层的通道数,每层都是3x3的卷积核,那么对于上面的部分和下面的部分,其层数间通道的关系满足:
然后就是核心操作了,其在上面部分和下面部分之间引入一个slice操作,这个操作将特征给分成了原来部分的1-1/s送入下面的模块,以及1/s和上一个Block的信息concat在一起,然后再加到增强模块的最后。论文说这样做的目的是为了保留部分上面的模块的信息,并且重利用前面Block的信息。
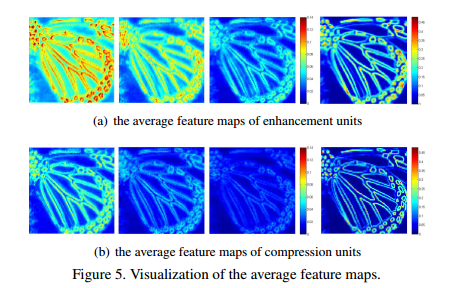
然后就是压缩模块,这个没什么好说的,就是1x1的卷积进行通道压缩,论文说这里是去除对于后面网络来说多余的信息。在具体训练时,这里D3,d和s分别设成64,16和4,而且对增强模块的第四层和第二层使用分组为4的分组卷积。最后是实验结论,简要来说就是增强模块学习图像的轮廓信息,压缩模块继续减小像素值,这里不再赘述,不过这里使用了一个T操作将网络中间的特征层可视化了,将3D tensor转换成了2D,这步操作我觉得很有意思,可以学习用来以后分析网络。