题目具体要求如下:

这道题有两种方法,第一种是使用sklearn调包求解权重系数,第二种是直接使用公式代入基函数求解。产生y的代码如下所示:
1 | import numpy as np |
然后是求解权重系数,使用公式直接求解代码如下,其中公式为$(X^T X+\lambda I)^{-1}X^T y$,注意掉注释的部分,是为方法2。
1 | def coffecient(lamda): |
然后就是求解多项式系数的曲线及其均值,总共是100组数据,每次都产生不同的系数,代码如下:
1 | def select(lamda): |
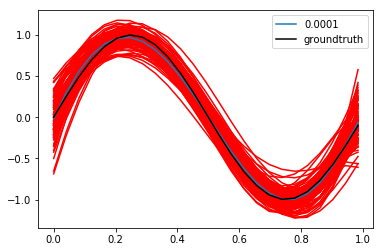
我们取lamda为0.0001,画出100个多项式的曲线及其平均值,以及目标曲线y=sin(2pix)的曲线,如下所示,其中蓝色为平均值曲线,黑色为groundtruth,红色为100个多项式曲线。
1 | plt.figure() |
<matplotlib.figure.Figure at 0x7f4ac450e910>
然后我们让lamda从0.001依次x10变到1,观察各lamda对应的多项式平均值变化趋势,次步先将上面的select里的plot注释,再执行下面代码,防止多个多项式的干扰,结果如下所示:
1 | plt.figure() |
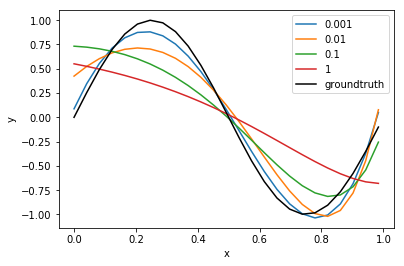
可以看出,lamda的值越小,其距离真实值的偏差越小,符合我们在课上学习得到的偏差,方差中对lamda作用的理解。
此外,将def coffecient(lamda):里注释的三行注释删去,同时去除上面的一行代码,是使用sklearn进行求解,图与上面一样,这里不再赘述。