VAE又被称为变分自动编码器,是除了GAN以外的另外一种生成模型方法。在VAE中,其使用KL散度作为损失,其可以测量两个概率分布之间的距离,越小越好。
VAE本质上和autoencoder非常类似,都是一个基于编解码的架构。但是VAE中间加入了一个latent vector,而这个部分则添加限制条件使其服从高斯分布。也就是说,当输入是P(x)时,通过产生后验分布P(z|x)的形式先得到z的分布,再得到x的分布,而这个分布需要学习两个参数,均值$\mu$和方差$\sigma^2$。如下所示:

这样,就可以通过最小化D(x,$x’$)的形式,将输入x还原出来,也就是说,这里VAE是为每个样本构造专属的正态分布,然后采样来重构。VAE 的名字中“变分”,是因为它的推导过程用到了 KL 散度及其性质,因为对KL散度求极值使用了变分法,虽然最后VAE其实和变分没什么关系。
那么使用高斯分布的具体含义是什么呢?这里在VAE中,其Encoder中的计算均值和计算方差的两个部分和GAN中的生成对抗两部分非常像。其本质上是对encoder中计算均值的部分添加噪声。使得decoder部分对噪声具有鲁棒性,而KL loss则相当于对encoder部分的一个正则,希望encoder部分出来的结果具有0均值。
这样,当decoder部分还没有训练好的时候(误差远大于KL loss),就会适当降低噪声也就是KL loss增加,使得拟合变得容易。而当decoder部分训练的比较好时,噪声就会增加,使得拟合变得困难,这样decoder部分生成的能力就会变强。VAE的本质如下所示:
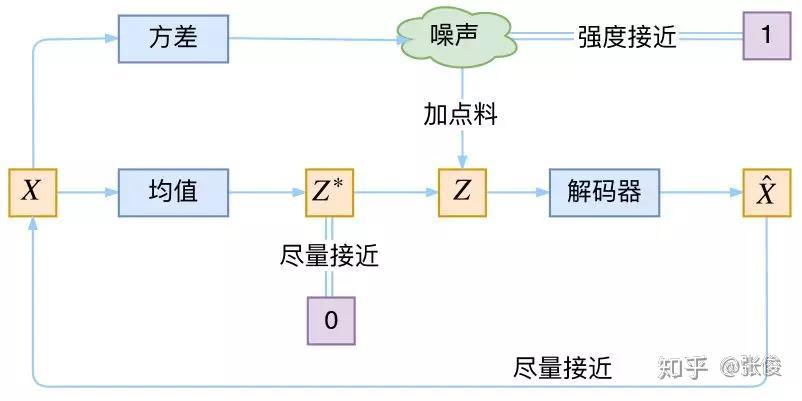
重构的过程是希望没噪声的,而 KL loss 则希望有高斯噪声的,两者是对立的。所以,VAE 跟 GAN 一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。
参考:
1.https://zhuanlan.zhihu.com/p/34998569
2.http://www.cnblogs.com/huangshiyu13/p/6209016.html