11月13日
Learning a Discriminative Feature Network for Semantic Segmentation(2018 CVPR)
来源:https://zhuanlan.zhihu.com/p/44490484
Discriminative Feature Network (DFN)包含两个子网络:
Smooth Network用于处理类内一致性问题,作者设计了一个具有通道注意力模块和全局平均池化的平滑网络,以选择更有判别性的特征
Border Network用于处理边界不清晰问题,借助多层语义边界监督区分边界两边的特征
为了应对这两个挑战(类内不一致,类间不清晰),将其看作一项把一致的语义标签分配给一类物体而不是每个单一像素的任务。需要把每个类别的像素看作一个整体,进而同时兼顾类内一致与类间差别,这意味任务需要具有判别性的特征。
Smooth Network用来解决类内不一致问题
需要多尺度和全局语境特征来编码局部和全局信息。比如,由于缺乏足够的语境信息,图1(a) 中的白色小图像块经常无法预测正确;
引入多尺度语境信息后,对于一定尺度的物体来说,大量的特征具有不同程度的判别力,其中一些特征可能导致预测错误。因此,有必要选择高效的判别特征。
出于上述两方面的考虑,Smooth Network设计成了U形结构
可以抓取不同尺度的语境信息,并通过全局平均池化抓取全局语境,此外,还使用了通道注意力模块(CAB),利用高层特征逐阶段地指导低层特征的选择。
Border Network负责区分外观相似但标签不同的相邻图像块
大多数现有方法把语义分割看作一种密集识别问题,通常忽略了对类间关系进行建模以,图 1(d) 为例,如果越来越多的全局语境信息整合进分类过程,相邻于显示器的电脑主机由于外观相似很容易被误认是显示器,因此,明确地使用语义边界指导特征的学习非常重要。这可以迫使网络增强两边特征的判别性,作者把语义边界loss整合进Border Network以学习更有判别性的特征,增大类间差别。
3.1. Smooth network
许多网络结构结合不同阶段的特征是仅仅是通过通道相加完成的,这样的操作忽略了不同阶段之间的差异性。本文嵌入了一个全局平均池化层,把 U 形架构扩展为 V 形架构。为网络引入最强的一致性约束作为指导。本文提出通道注意力模块以增强一致性。该设计结合相邻阶段的特征以计算通道注意力向量。高级特征给出语义指导选择低级特征,从而达到选择更具区分力的特征。
Channel attention block:
结构:
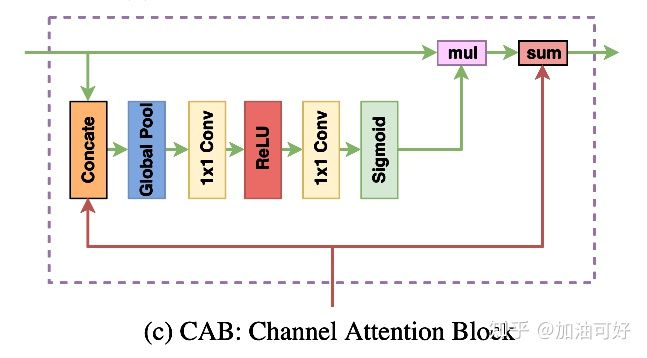
CAB 的设计目的是改变每一阶段的特征权重以优化一致性,如图 3 所示:
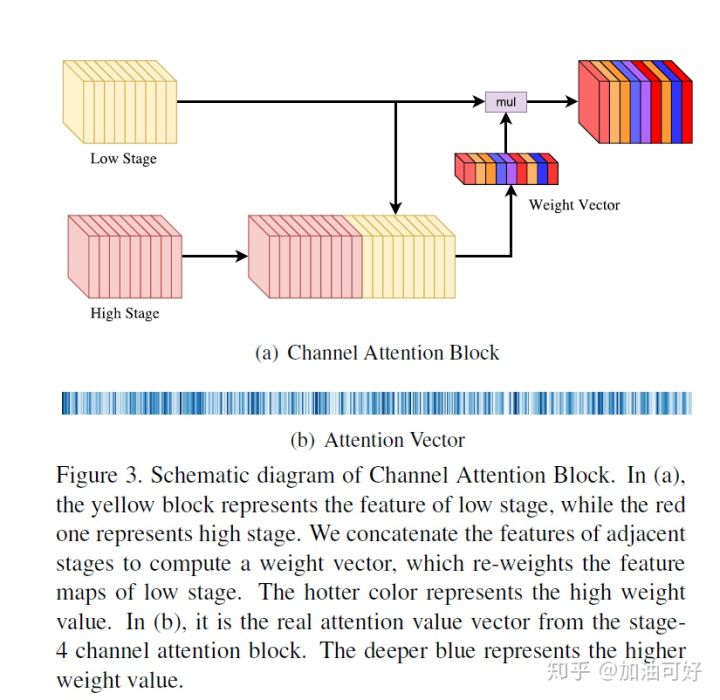
在 FCN 架构中,卷积算子输出了一个score map,给出每个像素在每一类别上的概率。这种方式实际意味着不同通道的权重是平等的。然而,不同阶段的特征判别力不同,造成预测的一致性各不相同。为实现类内一致预测,应该提取判别特征,并抑制非判别特征,从而可以逐阶段地获取判别特征以实现预测类内一致。
Refinement residual block:
特征网络中每一阶段的特征图全都经过 RRB,如图 2(b) 所示:
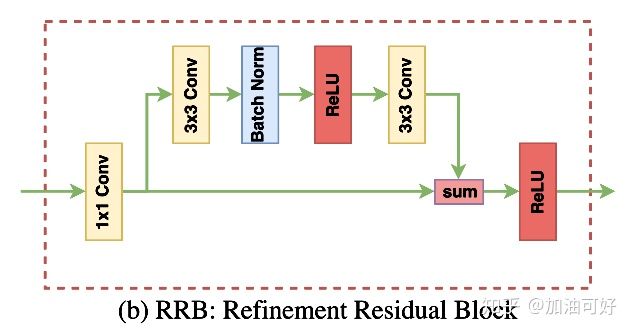
第1个组件是1x1卷积层,整合所有通道的信息,并把通道数量统一为 512。接着是一个基本的残差模块,可以优化特征图。该模块还可以强化每一阶段的识别能力。
3.2. Border network
本文的工作需要语义边界具有更多的语义含义,因此Border Network的设计是自下而上的。
它可以同时从低级阶段获取精确的边界信息和从高级阶段获取语义信息,从而消除一些缺乏语义信息的原始边界,高级阶段的语义信息可以逐阶段地优化低级阶段的细节边界信息,借助传统的图像处理方法,比如 Canny,作者可以从语义分割的groundtruth中获得网络的监督信号。
基于Smooth Network和Border Network,论文提出DFN:
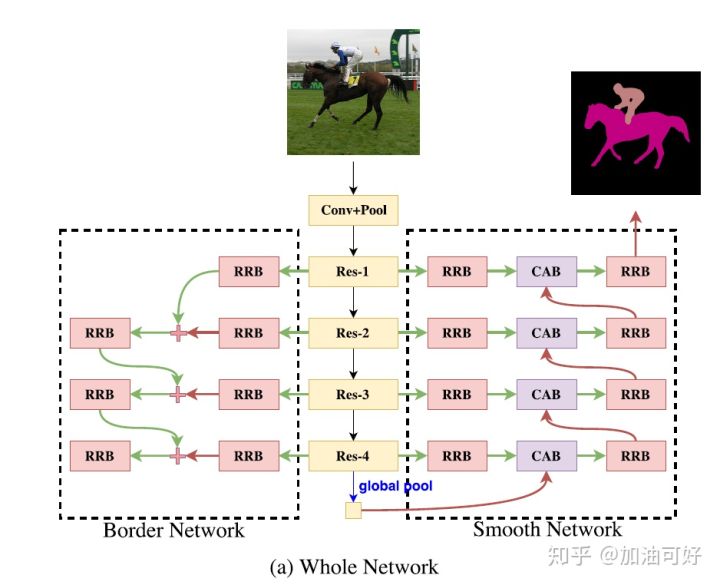
使用预训练的ResNet作为网络主干
Smooth NetWork:顶端使用了一个全局平均池化层捕获全局信息。使用channel attention block来改变通道权重
Border Network上,使用语义边界监督,网络获得更为精准的边界,得到的mask也更具区分度
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform(2018 CVPR)
来源:https://zhuanlan.zhihu.com/p/37661072
面向生成更自然真实纹理图像的超分辨率算法。本文提出了一种新的空间特征调制层(SFT),它能将额外的图像先验(比如语义分割概率图)有效地结合到网络中去,恢复出与所属语义类别特征一致的纹理。
空间特征调制
本文提出的空间特征调制层受到条件BN层的启发,但是条件BN层以及其他的特征调制层(比如FiLM),往往忽略了网络提取特征的空间信息,即对于同一个特征图的不同位置,调制的参数保持一致。但是超分辨率等底层视觉任务往往需要考虑更多的图像空间信息,并在不同的位置进行不同的处理。基于这个观点,本文提出了空间特征调制层,其结构如下图所示。
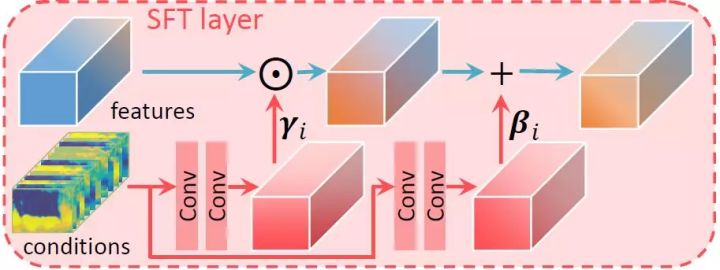
空间特征调制层对网络的中间特征进行仿射变换,变换的参数由额外的先验条件(如本文中考虑的语义分割概率图)经过若干层神经网络变换得到。
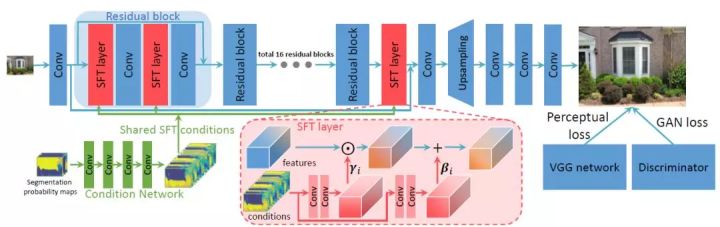
空间特征调制层可以方便地被集成至现有的超分辨率网络,如SRResNet等。图4是本文中使用的网络结构。为了提升算法效率,先将语义分割概率图经过一个Condition Network得到共享的中间条件,然后把这些条件“广播”至所有的SFT层。本文算法模型在网络的训练中,同时使用了perceptual loss和adversarial loss,被简称为SFT-GAN。
11月14日
Fully Convolutional Adaptation Networks for Semantic Segmentation(2018 cvpr)
来源:http://www.cvmart.net/community/article/detail/278
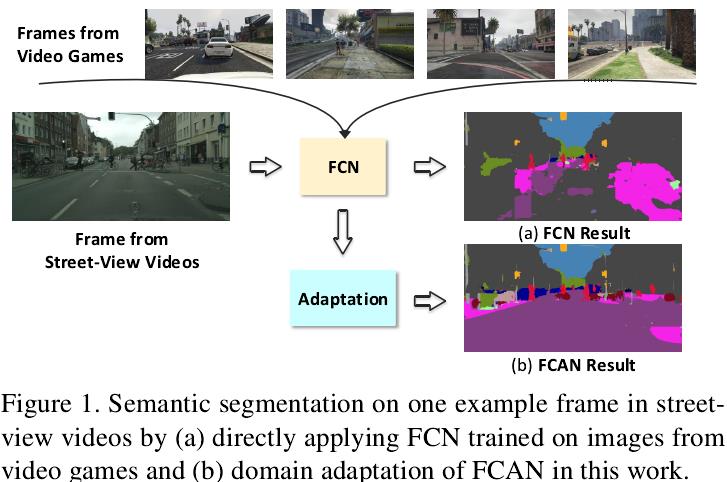
合成图像和真实图像的数据分布存在巨大的偏差,也叫domain shift,如何解决这一domain shift问题,使得利用合成数据训练得到的模型能很好地迁移到真实图像上,是本文探索的一个问题。
域适配(Domain Adaptation, DA)问题已经在图像分类任务上得到了广泛研究,今年CVPR上也有很多相关工作。其本质属于迁移学习的一种,问题设定是:如何使得源域(Source Domain)上训练好的分类器能够很好地迁移到没有标签数据的目标域上(Target Domain)上。这种域适配问题在语义分割中同样存在,在本文中具体体现为合成图像和真实图像直接的Domain Adaptation。
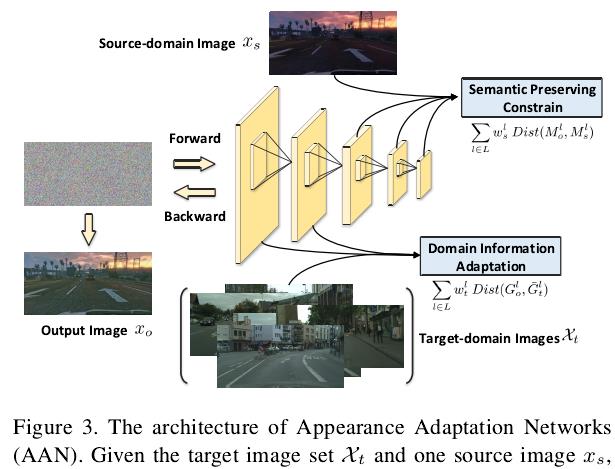
针对合成图像和真实图像之间的域适应问题,本文主要提出了两种域适应策略,分别是图像层面的域适应(Appearance Adaptation)和特征表示层面的域适应(Representation Adaptation),具体实现为两个网络架构:图像域适应网络(Appearance Adaptation Networks,AAN)和特征适应网络(Representation Adaptation Networks,RAN)。整体网络架构如下图所示:
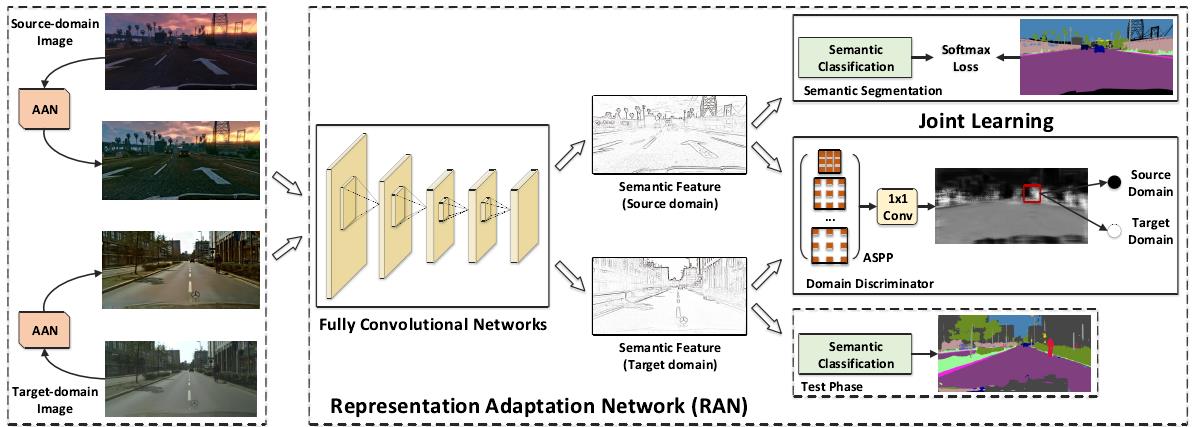
上图给出了本文方法的处理流程,左侧的AAN负责对合成图像进行转换,使得生成的图像在内容上依然保留原始合成图像的内容,但在风格上要非常接近真实场景中的图像,右侧的RAN本质上是一个生成对抗网络GAN,其目的都是使得基础网络FCN提取的特征具有域不变性,也即要使得不管是来自合成图像还是来自真实图像,提取的特征应该分布在同一个特征空间上。结合上图下面重点论述本文提出的以上两个域适应网络:
1、Appearance Adaptation Networks
图3展示了图像域适应网络AAN的具体细节和处理流程,熟悉style transfer的同学其实已经发现了它本质上就是一个图像风格转换网络,其实现思路也是和CVPR2016的这篇文章[1]类似的,这里简单阐明一下实现思路:输入是一张高斯白噪声图像,输出图像是在网络反向传播的过程中不断更新得到的:
2、Representation Adaptation Networks
RAN的目的是为了使得基础网络FCN提取的特征具有域不变性,其本质上是个生成对抗网络,其中的生成器G是上图中的基础网络Fully Convolutional Networks,用于提取来自两个域的图像特征;判别器D是上图中的Domain Discriminator,用于判别特征来自源域还是目标域。对于源域的合成图像而言,该特征分别输入两个分支:一是上图中的语义分割分支,利用合成图像的标签进行有监督训练,损失函数是正常的逐像素分类损失;二是输入上图中的Domain Discriminator,同时来自目标域的图像特征也输入到Domain Discriminator,生成器要利用生成的特征使得Domain Discriminator判别不出来来自哪个域,而Domain Discriminator则要尽可能判别正确,这就构成了一个对抗过程。
在测试时,将真实图像输入基础网络和语义分割分支就可以得到结果。
总结展望
本文贡献:(1)提出了语义分割任务中的域适应问题:如何利用合成数据有效提升真实场景中的语义分割性能;(2)提出了两个层面的域适应策略(图像层面的域适应和特征层面的域适应),用于解决该问题。
Learning a Discriminative Prior for Blind Image Deblurring(2018 cvpr)
来源:http://www.cvmart.net/community/article/detail/206
盲图像去模糊(blind image deblurring)是图像处理和计算机视觉领域中的一个经典问题,它的目标是将模糊输入中隐藏的图像进行恢复。
研究者将图像先验表示为能够区分清晰图像和模糊图像的二值分类器。具体来说,他们训练深度卷积神经网络来分类模糊图像 (标记为 1 ) 和清晰图像 (标记为 0 )。由于基于 MAP(最大后验)的去模糊方法通常使用 coarse-to-fine(由粗到精)策略,因此在 MAP 框架中插入具有全连接层的 CNN 无法处理不同大小的输入图像。为了解决这个问题,他们在 CNN 中采用了全局平均池化层 [ 21 ],以允许学习的分类器处理不同大小的输入。此外,为了使分类器对不同输入图像尺寸具有更强的鲁棒性,他们还采用多尺度训练策略。然后将学习到的 CNN 分类器作为 MAP(最大后验)框架中潜在图像对应的正则项。如图 1 所示,本文提出的图像先验比目前最先进的人工设计的先验 [ 27 ] 更具区分性。
然而,使用学习到的图像先验去优化这个去模糊方法是很困难的,因为这里涉及到了一个非线性 CNN。因此,本文提出了一种基于半二次方分裂法(half-quadratic splitting method)和梯度下降算法的高效数值算法。这个算法在实际使用中可以快速地收敛,并且可以应用在不同的场景中。此外,它还可以直接应用在非均匀去模糊任务中。
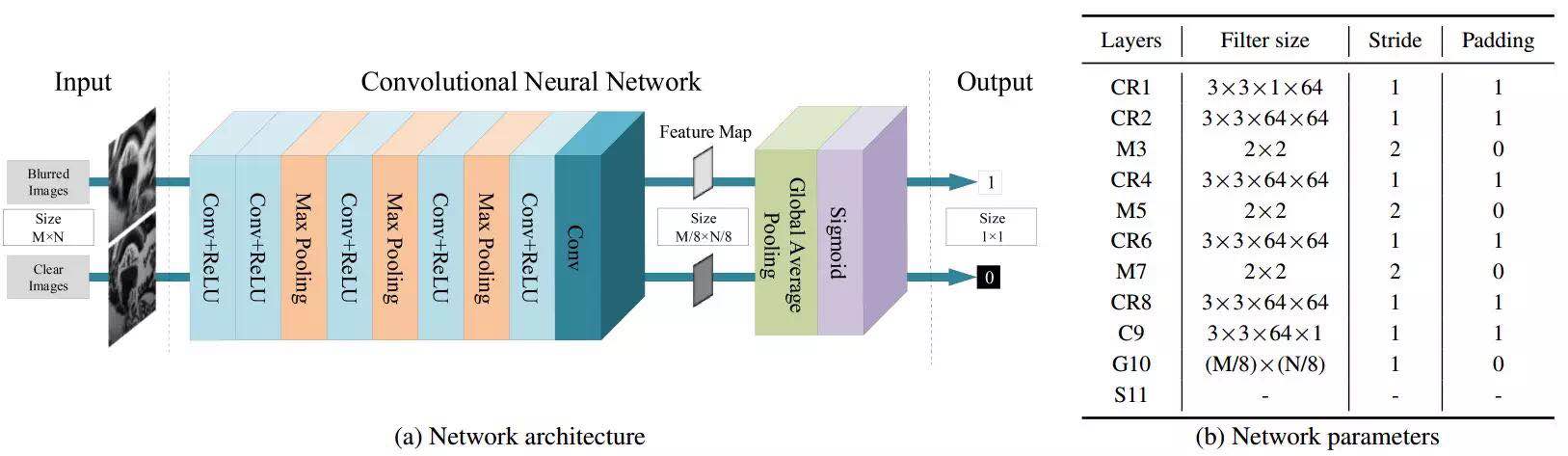
二分类网络
我们的目标是通过卷积神经网络来训练一个二分类器。这个网络以图像作为输入,并输出一个标量数值,这个数值代表的是输入图像是模糊图像的概率。因为我们的目标是将这个网络作为一种先验嵌入到由粗到精的 MAP(最大后验)框架中,所以这个网络应该具备处理不同大小输入图像的能力。所以,我们将分类其中常用的全连接层用全局平均池化层代替 [21]。全局平均池化层在 sigmoid 层之前将不同大小的特征图转换成一个固定的大小。此外,全局平均池化层中没有额外的参数,这样就消除了过拟合问题。
11月15日
exploring visual relationship for image captioning(2018 ECCV)
网络如下,编码器-解码器图像描述系统可分为三部分:(1)物体检测模块;(2)基于图卷积网络的图像编码器模块;(3)基于长短时记忆网络的解码器模块。对于输入的图像,物体检测模块首先检测图像中包含的物体,并获得每个物体对应的区域级别的特征。然后,针对检测出来的多个物体,我们会构建出物体间的语义关系图和空间关系图(具体构建方法见后)。接着在基于图卷积网络的图像编码器模块中,图卷积网络会分别作用于物体间的语义关系图和空间关系图上,将两两物体间的语义关系和空间关系融入到对应物体的区域级别的特征,实现对物体区域级别特征的进一步编码。在获得了来自于语义关系图或者空间关系图上蕴含有物体间关系的区域级别特征后,我们将这一组编码后的物体区域级别特征输入基于长短时记忆网络的解码器模块,主要利用两层的长短时记忆网络来将输入的图像区域级别特征解码为对应的文本描述。
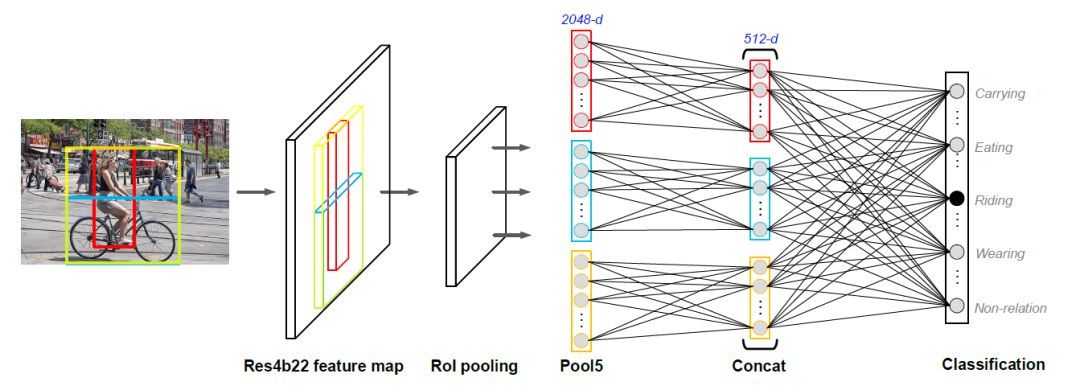
对于物体间语义关系图,我们主要利用了如下的语义关系分类模型来实现两两物体间语义关系的判断。其输入为两个物体和它们共同覆盖区域特征的联结,以此为基础判断这两个物体间是否具有语义关系以及具有哪种语义关系。最后再对所有具有语义关系的物体间连接一条有向边,完成最终物体间语义关系图的构建。
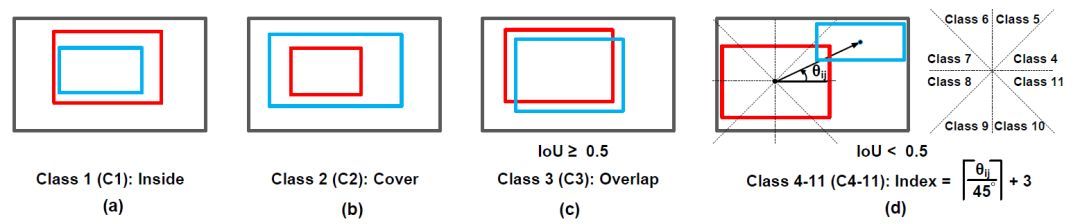
对于物体间空间关系图,我们直接依照两两物体间的空间相对位置关系,划分出了如下十一种不同的空间关系,这其中不仅具有包含与被包含,互相重叠的空间关系,还对八种不同的空间相对角度关系进行了细致的划分。最终的空间关系图则依据这十一种空间关系进行构建。
Adaptive Affinity Fields for Semantic Segmentation(2018 ECCV)
来源:http://www.cvmart.net/community/article/detail/333
与在单个像素上强制学习语义类别并在相邻像素之间匹配类别的现有方法不同,提出的自适应相似场(Adaptive Affinity Fields, AAF)的概念来匹配标签空间中的相邻像素之间的语义关系。
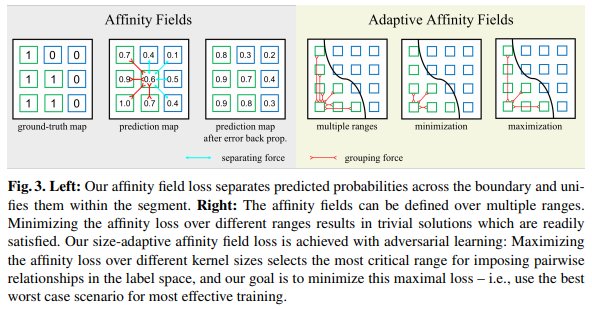
同时本文使用对抗性学习为每个语义类别选择最佳的亲和力范围。将此概念转化为一个极小极大的优化问题,利用最好的最坏情况学习(best worst-case learning)情境优化语义分割神经网络。
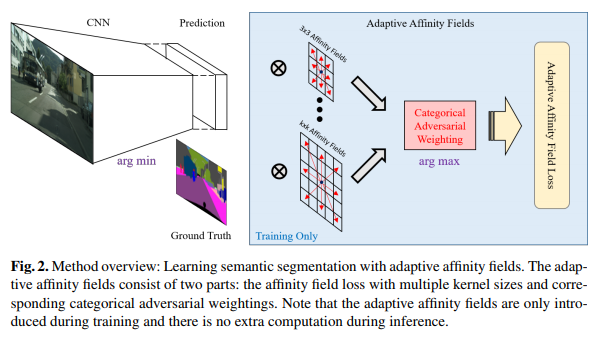
AAF算法仅在训练期间多了一些步骤,不需要额外的参数,也易于训练。
11月16日
Learning a Single Convolutional Super-Resolution Network for Multiple Degradations (2018 CVPR)
来源:https://blog.csdn.net/sinat_25838589/article/details/81069842
有的基于深度卷积神经网络的图像超分辨方法基本上是假设低分辨图片是由高分辨率图片通过双三次插值的方法下采样得到的。这就不可避免的造成了当真正的低分辨率图片不遵循双三次插值下采样时,模型的表现将变得不好。我们提出了一种维度拉长策略,将模糊和噪声作为输入。这种方法可以应对多倍和空间改变的退化模型,显然提高了实用性。
本文的主要贡献有:
1、我们提出了一种简单有效并且可缩放的CNN超分辨模型。
2、我们提出了一种维度拉长策略取匹配低分辨率图片与模糊核和噪声之间的不匹配关系。
3、我们展示了使用合成的训练数据不仅在合成的低分辨率图片中展示出完美的结果,也在真实低分辨率图片中表现出合适的结果。
虽然模糊核和噪声在图像超分辨领域中被认为是成功的关键,但是很少有方法将两者结合去构造网络结构。我们的方法考虑到一个更通用的退化模型,使用了一个更有效的方式去调整退化参数。
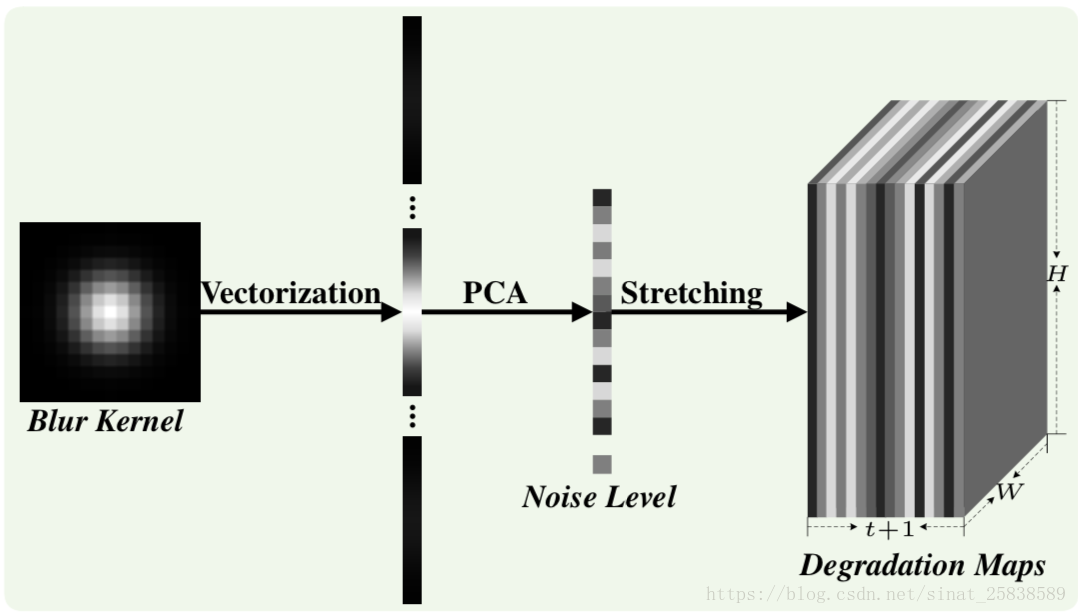
假设输入包括大小为p*p的模糊核,一个水平为σ的噪声,和一个大小为W×H×C的低分辨率图片,C表示图片通道数量。如下图 。首先模糊核被拉伸为p²×1的向量,然后通过PCA投影到t维的线性空间。之后低维度的向量和噪声被延展到一个维度为W×H×(t+1)的退化映射中。这样就可以使CNN支持处理3种输入。
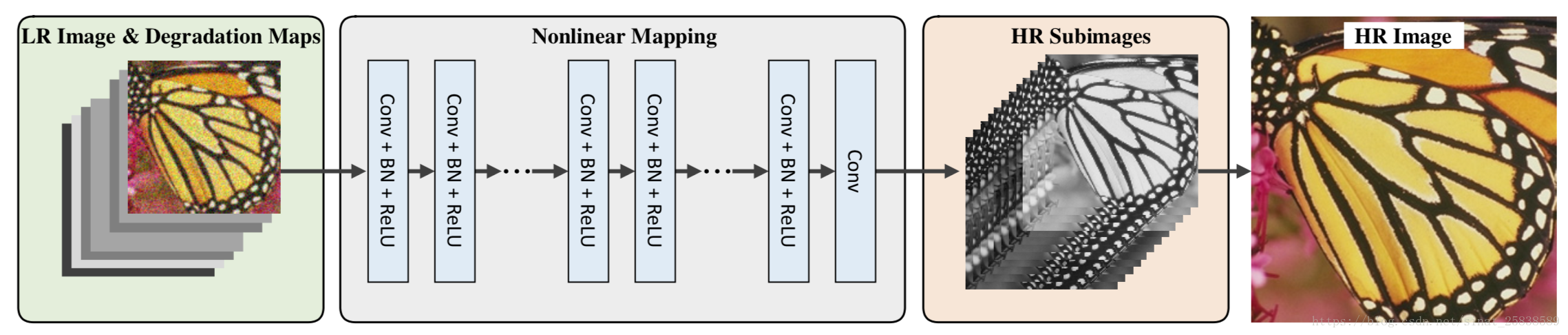
输入W×H×(t+1)维度,中间层如图,最后经过子像素卷积生成高分辨率图片。 特别是,我们还通过去除第一个卷积滤波器中的噪声水平图的连接以及使用新的训练数据进行微调来学习无噪声衰减的模型,即SRMDNF。该网络没有使用残差结构和使用双三次插值下采样得到的低分辨率图片。
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
来源:https://blog.csdn.net/lhanchao/article/details/82863476
这是image caption的开山之作,架构如下:
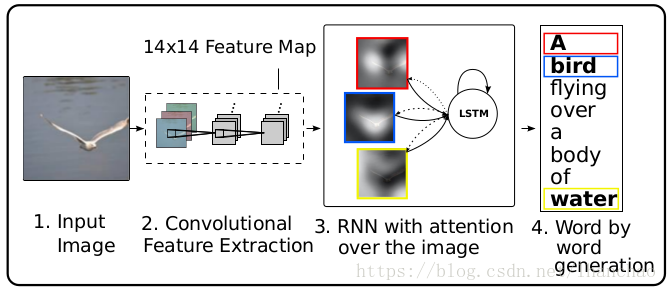
可以看出整个Caption的生成流程主要分为两个步骤:(1)CNN提取特征;(2)带有Attention机制的RNN解码特征。这种流程又称为Encoder-Decoder模型,该模型最早用于NLP的机器翻译任务中,后面广泛的应用于机器翻译、语音识别以及我们这里的Image Caption任务中。
在Image Caption任务中也通常使用CNN作为编码器对图像进行特征提取(即编码为特征)。在Show attend and tell一文中使用的是经过预训练的VGGNet作为编码器提取图像的特征,可以得到一系列的特征向量a。
Attention机制跟人眼的注意力机制很像,当我们在观察一个东西的时候,是关注这个东西,视野中其他的部分就会忽略掉,Attention机制做的是生成一组权重,对需要关注的部分给予较高的权重,对不需要关注的部分给予较低的权重。如图所示,当生成某个特定的单词时,Attention给出的权重较高的部分会在图像中该单词对应的特定区域,即该单词主要是由这片区域对应的特征生成的。 在Show,attend and tell一文中介绍了两种Attention方式:hard attention和soft attention。这里只介绍soft attention。
