2月18日
新全景分割算法 DeeperLab
来源: https://zhuanlan.zhihu.com/p/56887843
提出了一种用于image parsing(图像解析)的 single-shot, bottom-up 的方法。Whole image parsing(整幅图像解析),也称为全景分割,涵盖了 “stuff” 类的语义分割任务和 “thing” 类的实例分割,为图像中的每个像素分配语义和实例标签。
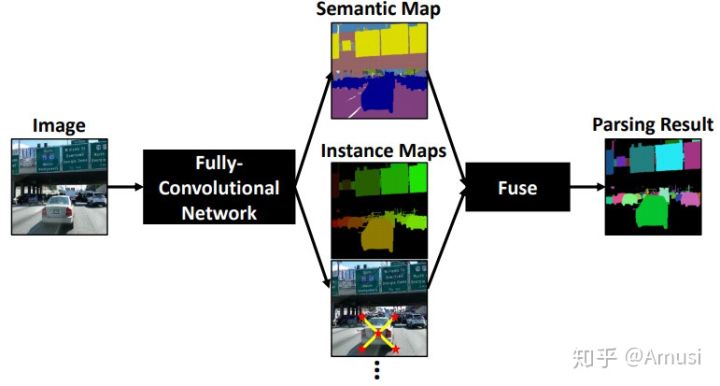
主要贡献:
1)我们为高效的 image parsers 提出了几种神经网络设计策略,特别是减少了高分辨率输入的内存占用。这些创新包括广泛应用 depthwise separable convolution(深度可分离卷积),使用带有简单的两层预测头的共享解码器输出,扩大 kernel 大小而不是使网络更深,采用 spaceto-depth and depth-to space 而不是上采样,并采用 hard data mining 。还提供了详细的 ablation(消融)研究,以验证这些策略在实践中的作用。
2)我们基于提出的设计策略,提出了一种高效的 single-shot, bottom-up image parser:DeeperLab。例如,在 Mapillary Vistas 数据集上,基于Xception-71 [5,6,7]的模型实现了31.95%PQ(val)/ 31.6%(测试)和55.26%PC(val),每秒3帧(fps)在GPU上。我们的新型更广泛的基于MobileNetV2 [8]的模型可以实现接近实时的性能(GPU上为22.61 fps),当然精度会有所降低。
3)我们提出了一种新的度量标准:Parsing Covering,用于从基于区域的角度评估 image parsing 结果。
Multiple Granularity Descriptors for Fine-grained Categorization
来源:https://zhuanlan.zhihu.com/p/56501461
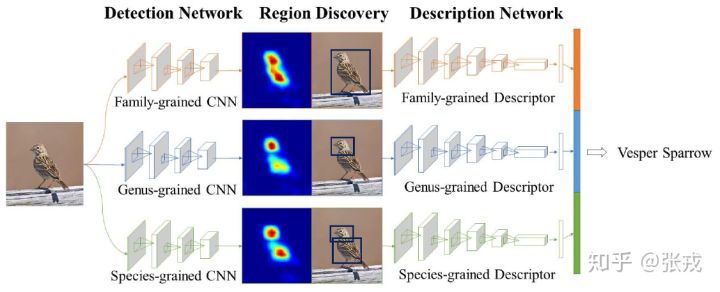
做鸟类的分类工作,鸟类的区分是按照一定的层次关系来进行的,粗糙来看,有科 -> 属 -> 种三个层次结构。因此,在设计网络结构的过程中,需要有并行的网络结构,分别对应科,属,种三个层次。从前往后的顺序是检测网络(Detection Network),区域发现(Region Discovery),描述网络(Description Network)。并行的结构是 Family-grained CNN + Family-grained Descriptor,Genus-grained CNN + Genus-grained Descriptor,Species-grained CNN + Species-grained Descriptor。而在区域发现的地方,作者使用了 energy 的思想,让神经网络分别聚焦在图片中的不同部分,最终的到鸟类的预测结果。
2月19日
细粒度识别之Local Attention Network
来源: https://zhuanlan.zhihu.com/p/57086099
主要贡献是提出了弱监督局部注意力网络,其能够自动关注物体的大量判别部位。并且通过提出注意力中心损失和注意力dropout来监督注意力图的学习过程。在这个方法中,物体部位由位置图来表示,而非边界框。采用局部注意力池化的方式来提取部位特征,这使得模型更容易训练。已经有相关文献表明,卷积特征图通常对应于一种潜在的几何分布或视觉模式。所以,作者期望每个注意力图表示一个独特的物体部位,所以增加了注意力中心损失约束,以确保每个部位特征接近于全局部位中心。为了防止注意力图只集中在相同物体上,提出了attention dropout策略,在训练过程中随机丢弃注意力图,这提供了任何物体部位不可见的可能情况,并防止了模型过拟合。模型结构如下:
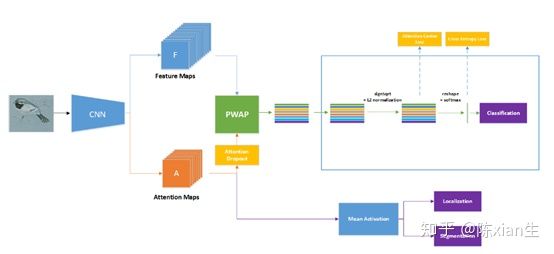
整体的模型如上图所示,输入图像通过骨干网络得到特征图和注意力图,然后对注意力图采用dropout策略,其次将注意力dropout和特征图采用局部注意力池化的方法得到图像的特征表示,然后将特征进行sign-sqrt和 l_{2} 归一化得到最终的特征表示,最后使用注意力中心损失和交叉熵损失来训练网络。而下面的分支是用来实现目标定位和分割。
(1) 局部注意力池化
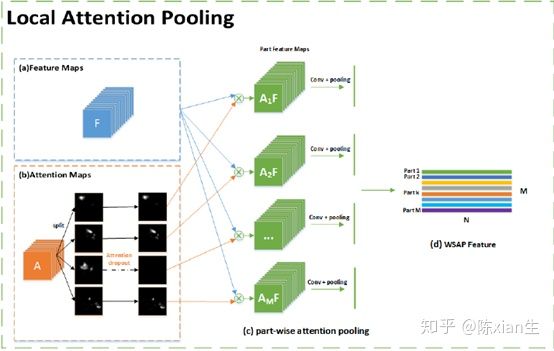
通过一个或者多个卷积操作从骨干网络中生成注意力图。注意力图可以表示为$ A=\left[ a{1}, a{2},…,a{M} \right]$ , M 表示注意力图的总数。 a{k} 可以反映物体第 k 个部位的位置。
然后将特征图 F 和注意力图 a{k} 逐元素相乘产生部位特征图 $F{k}^{A}=a{k} \odot F \left( k=1,2,…,M \right)$ ,这里的 $\odot$ 表示两个矩阵的元素积。
最后使用特征提取函数 $g{k}$ 来获取第 k 个部位的特征 $f{k}$,$f{k}=g{k}\left( F{k}^{A} \right)$。 $g{k}$ 可以是全局平均池化、全局最大池化或者是卷积操作。
(2) 注意力中心损失
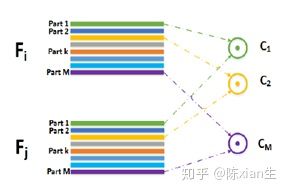
如上图所示,假设目前得到两张图像的特征 $F{i}$ 和 $F{j}$ ,每个特征都是由 M 个部分组成的,而注意力中心损失希望实现的效果是 $F{i}$ 中的 part1 和 $F_{j}$ 中的 part1 比较接近, part2 和 part2 接近,等等。提出这一算法的背景是:作者希望同一特征图中每个不同的 part 能够关注目标不同的部位,并且不同特征图中相同的 part 应该关注的部位是一样的。
3月3日
AUNet for Panoptic Segmentation
来源:https://www.zhihu.com/topic/19590195/hot
全景分割(panoptic segmentation)是一项新的视觉任务,主要是对图像或视频中的前景物体(foreground objects)比如人、车、动物等可数名词类别进行实例级别的分割,这种物体我们称之为“things”,同时也对背景物体(background object)比如天空、道路、树、草地等不可数类别名词类别进行语义级别的分割,这种物体我们称之为“stuff”。
目前主流的方法是用不同的model分别处理Semantic segmentation(background)和instance segmentation(foreground),然后再人工的merge和hack重叠区域得到最后的分割结果。之前的方法的一个共同点是前景和背景分割结果是用不同的model得到,两者之间几乎没有关联。
在这篇文章中作者提出了一个统一的端到端框架AUNet,将Semantic segmentation和instance segmentation融合,利用foreground context information 提供的线索提高background stuff的分割效果。
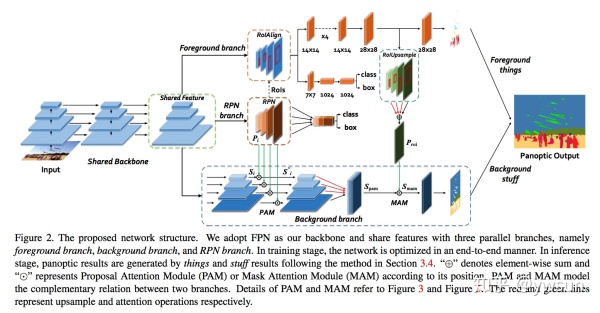
模型整体结构如图所示,backbone采用FPN结构,可以更好的处理不同scale的物体,提高feature extraction的能力。整体来讲,模型是一个Mask R-CNN和background segmentation branch的并行结构。Mask R-CNN负责前景分割,得到instance segmentation结果,同时提供foreground information给background segmentation branch。两个分支的结果最后通过人工hack的方式处理冲突区域,得到最后的结果。
RoIAlign是为了解决RoI pooling中出现misalignment的问题,通过sample和bilinear interpolation的方式使得pooling出来的size-fixed feature更准确。为了更好的利用mask携带的foreground信息,需要将mxm固定大小的mask变成W’xH’的feature map方便与background branch融合,这就是RoIUpsample的作用。
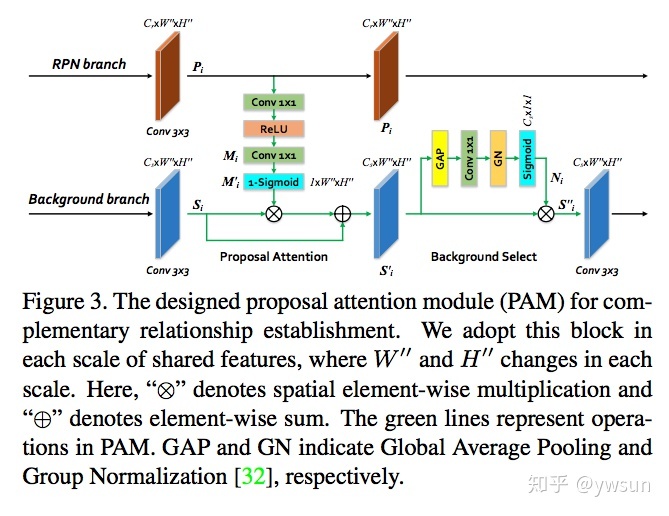
PAM没有什么特别的地方,就是利用RPN的coarse foreground信息指导background branch,相当于添加了空间attention,后面的background select相当于SE block,其中采用了GN,操作比较简单。
Mask Attention Module
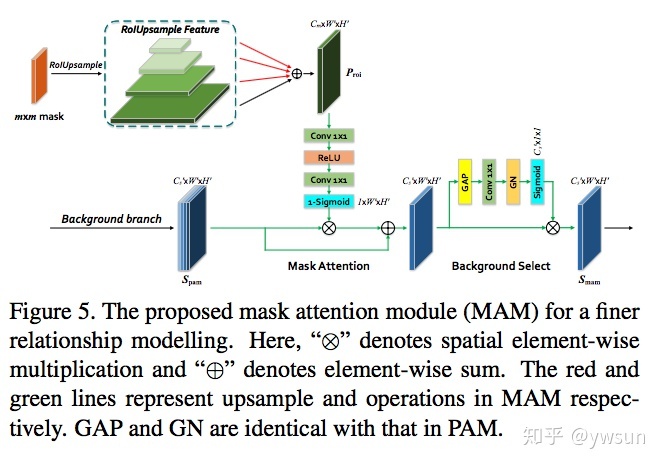
MAM先对mask upsample恢复到原来的特征图大小,后面的操作基本和PAM一样,这样foreground的信息就融合进了background branch里面。