这是2017 ICCV的一篇论文,感觉还是有点意思的,简要理解如下。
论文要解决的问题是多曝光融合转换的方法需要很多LDR图像去获得整个场景的动态范围,其次获得更多曝光的图像会消耗很多。这篇文章的基本思路是做无监督的图像融合,整体结构如下所示:
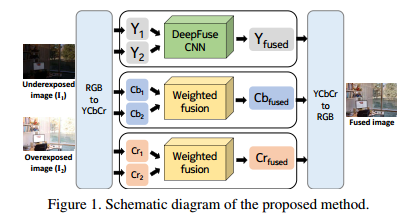
传统的方法是计算各个图像的权重然后局部或者全局的融合在一起。这里的思路是,图像的光照差异在L通道上比其他通道上的差异要大,而且结构信息主要也保留在L通道上,所以这里网络送进的是L通道的信息,其他两个通道通过加权方式融合获得最终的对应通道图。送入L通道信息的网络如下所示:
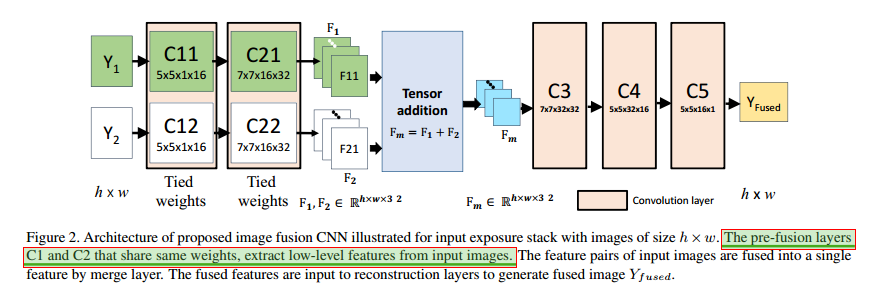
网络是两个分支输入,两支网络使用相同的权重,这个网络有三个优点,首先是可以让网络学习相同的fearure类型对于一个输入对。其次,是两个特征相加的融合效果更好。最后,网络的参数量少,收敛快。融合的特征通过三个CNN层获得最后的输出。
对于Loss,这里很有意思,将输出图表示为$y_f$,输入图经过一系列变换转换为$\hat{y}$(详见论文),最后的Loss是它们两个的基于SSIM的loss。这样转换的目的是为了获得全局的光照一致性。其他部分见论文。