这是2017 ICCV一篇做deblur的论文,说的很酷炫,其实个人感觉原理也就那样,通过sparse的特征来获得模糊核下的具有代表性的特征,通过生成网络去获得和该特征类似的特征,然后经过解码网络实现。
单图的图像deblur问题一直很challenging,为其需要从一个模糊核模糊过后的图像估计出latent image。目前已有的方法都是设计先验去估计出这个inverse problem的参数,但是其缺点各个先验参数需要调整到足够好,且非常耗费时间。基于字典学习的方法学习一个字典对(从模糊和clean的图像里),从而获得它们sparse特征的关联性,但是缺点是只能获得线性变换的特征。基于深度学习的方法则只是在估计简单的模糊核,而没有考虑空间的各异性,因此模糊核估计错误会导致效果变得很差。因此论文的核心思想是,学习与模糊变换性无关的特征,再使用深度网络实现端到端的学习。
Blur-invariant Feature Learning
字典学习deblur的目标就是获得与blur因素无关的图像的特征,但是其只能线性。这里通过深度网络实现非线性的特征获得图像的domain信息。通过自编码器获得这种特征之后,然后是通过GAN让blur的图像的特征尽可能和clean图像的特征接近。整体结构图如下,也就是说,这里在自编码器阶段,通过$D^-$去将输入的clean图像映射到sparse特征,然后通过解码器$D$重建出输入。而对于GAN阶段,这里也通过生成器将输入blur图映射到sparse空间,然后通过训练好的decoder重建出deblur后的图像。这样做的优点是不需要选择先验,直接回归出clean的图像,同时也节省了很多计算量。
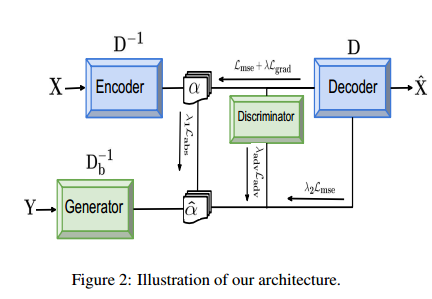
Network Architecture
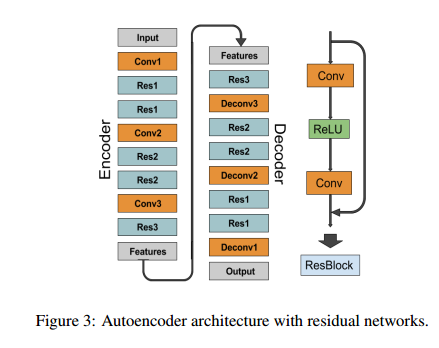
网络包括一个自编码器和一个GAN网络,这里的自编码器网络如下图所示,其中使用了reblock去改进特征的流向。
在GAN网络部分,这里使用了cGAN,从而使得训练过程保持稳定。论文原本也是想直接使用clean的图像用作GAN训练的指导,但是GAN在低维图像下会变得不稳定,所以这里使用了高维数据,GAN在高维数据下训练会更加稳定。这样生成器产生的feature就会和清晰的图像很像,然后解码恢复出原有的图像。
这里自编码器部分,使用$L{mse}+\lambda L{grad}$作为损失函数,后一项的目的是为了保边。输入图里还加入了噪声。对于GAN loss,这里是$\lambda{adv}L{adv}+\lambda1L{abs}+\lambda2 L{mse}$,其中第一项和第二项是作用于feature上的,用来获得更加close的特征,第三项作用在输出,用来对生成器做finetune。