虽然本人目前的方向是图像增强,但是个人感觉还是要多了解别的方向的东西,有些思路可以借鉴到后面的工作中。这里简要参考别人的博客来了解一下常见的图像分割网络的结构和原理。
FCN
这是最早用来做分割的网络了。FCN的原理就是,将传统的CNN用于分类的全连接层转换成卷积层,具体操作是将最后的全连接层变成核大小为1的卷积层,即卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。如下图所示:

将图像转换成feature而不是全连接层,更有助于获得每个feature上位置的类别信息。因为没有全连接操作,所以这里称为全卷积网络。经过多次卷积和池化之后,得到的feature已经很小了,这里通过反卷积的方法进行上采样,获得原来的尺寸大小。具体来说,就是原图像分辨率在多次卷积池化之后,尺寸分别缩小为原来的2,4,8,16和32倍。对最后一层图像做32倍上采样,就可以得到和原图一样的大小。
由于最后进行32倍下采样损失的细节太多,所以上采样得到的原图不够精细,这里作者还将16倍和8倍的输出也进行反卷积,如下图所示:
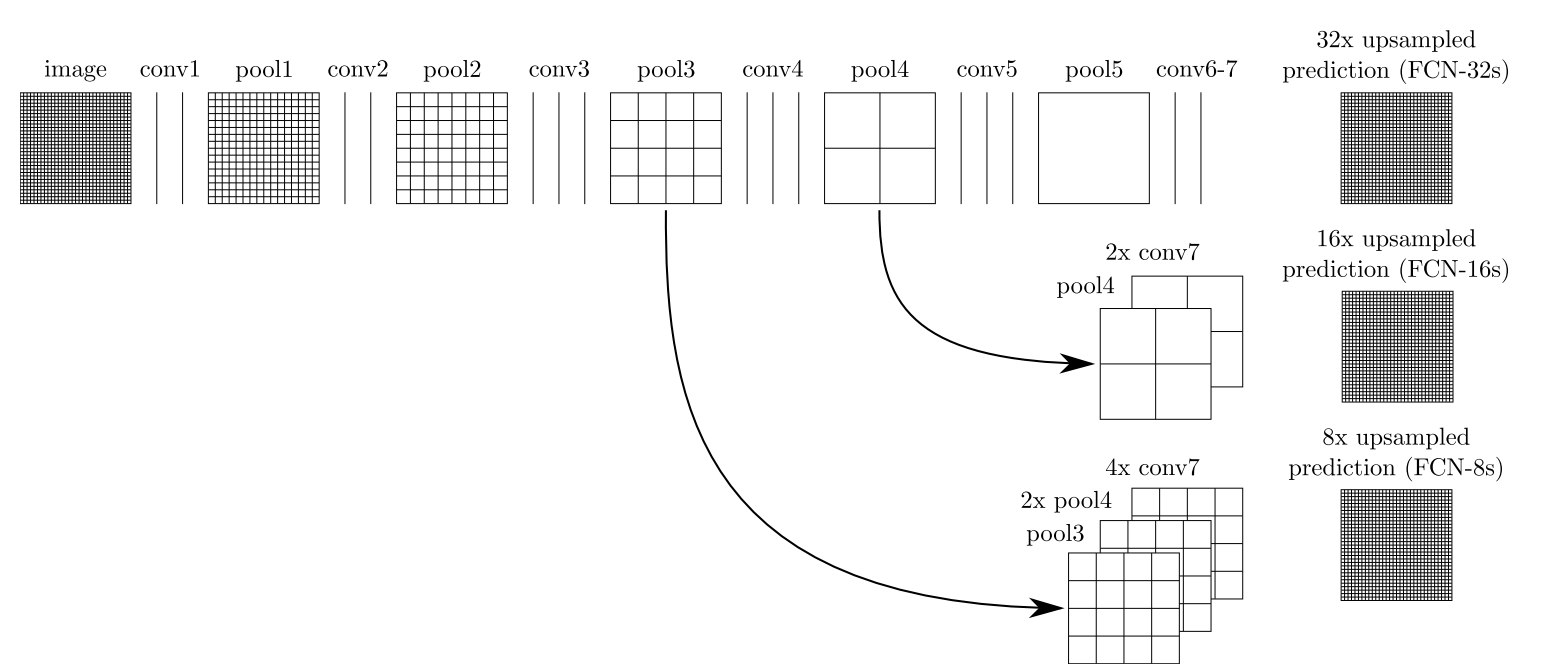
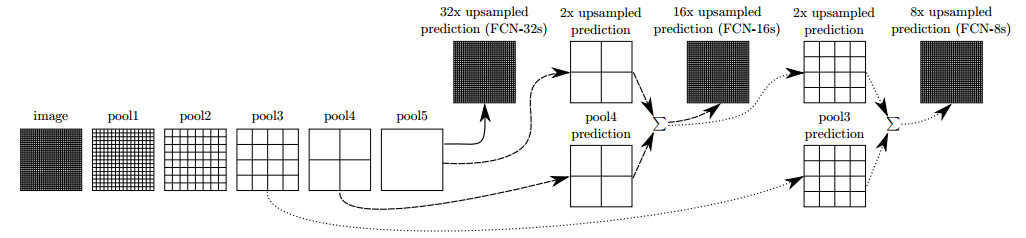
在具体进行操作时,FCN16s是将32倍下采样的结果和两倍上采样和16倍下采样的结果1x1卷积后相加,然后再放大16倍。FCN-8s的结果是将上述相加的结果进行两倍上采样再和8倍下采样的结果相加,然后再放大8倍。具体如下图所示:
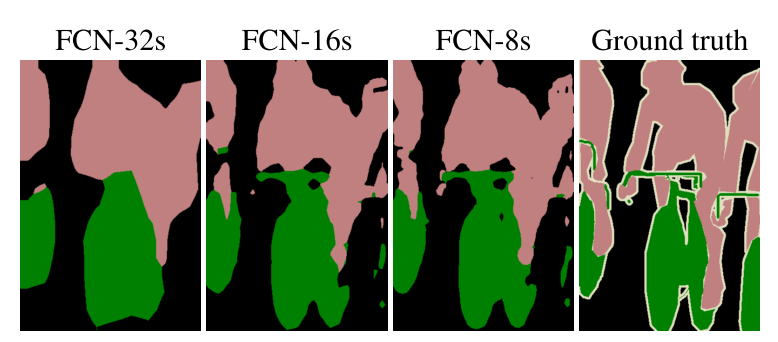
从下图可以看出FCN-8s的效果比较好,更为精细。
FCN存在的问题就是分割还不够精细,同时也没考虑像素之间的关系,缺少空间一致性。
Segnet
本来U-net也是一个经典的分割网络,不过在之前已经学习过了。这里的segnet一样也是包括encoder和decoder,encoder网络使用VGG网络的前13层,每个编码器层对应一个解码器层。编码器部分包括数个卷积层、BNc层、RELU和池化层组成,这里的池化层使用的是2x2的max-pooling,因此会导致边界细节损失变大。所以这里采用最大池化层的池化索引进行上采样,上采样的过程不需要学习。上采样得到的稀疏图通过滤波器卷积最终获得稠密的特征图。网络的整体结构如下所示:

所谓的池化索引,就是在最大池化的过程中,将选定的最大特征值的位置保存下来,即保存最大特征值在2x2的filter中的相对位置。具体如下图所示:
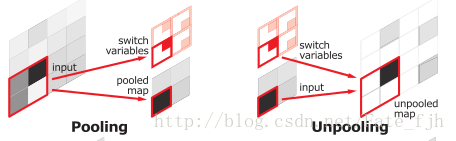
最大池化是为了获得空间位移的平移不变,对比FCN的反卷积可以发现这里使用Unpooling用到index信息,直接将数据放回相应的位置,这样上采样就不需要训练学习。如下图所示:
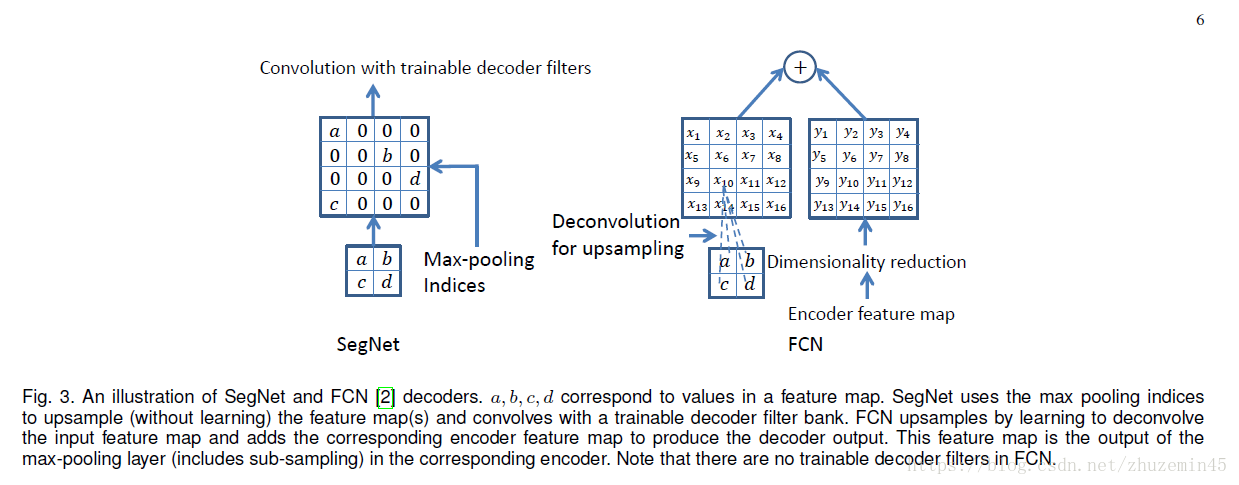
使用池化索引的上采样方式,可以提高边缘刻画度,减少训练的参数,且可以应用到任何编码-解码网络中。最后将输出的特征图输入softmax层,对每个像素进行分类,得到每个像素属于K类的概率。
参考:
1.https://blog.csdn.net/taigw/article/details/51401448
2.https://blog.csdn.net/zizi7/article/details/77093447
3.https://blog.csdn.net/cv_family_z/article/details/72897201
4.https://blog.csdn.net/zhuzemin45/article/details/79709874