2019 ICCV的论文,用于检测文字的SR,功能很实用,idea感觉比较水。一句话概况就是,因为目标是对文本进行SR提高文本识别的准确率,所以添加一个文本识别的识别器作为一个loss。整体结构如下所示:
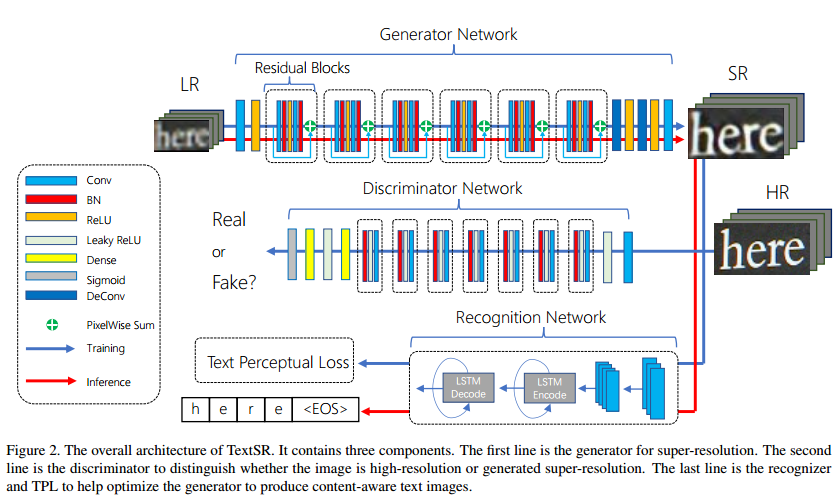
如上图所示,整张图分为生成器部分,判别器部分和识别网络部分,蓝色的线是训练部分,红色的线是测试部分。生成器就是生成SR图像的,判别器也是和SRGAN的差不多,最后加上一个识别器,通过识别准确率引导文本变清晰,其实和VGG loss是一个类型的。所以也如论文后面的实验所示,通过这个loss,提高了文本识别的准确率,以及视觉效果。
本来不想再写实验的,但是看了一下实验感觉有点怪。就是,其对比的方法是SRGAN,通过这个loss实现感官和识别效果超过SRGAN是必然的,但是缺少更多的和STOA的SR方法对比,以及和只用L2 loss的对比,这一点感觉实验做的不是很充足。