论文原地址:https://www.cmlab.csie.ntu.edu.tw/project/Deep-Photo-Enhancer/CVPR-2018-DPE.pdf
这篇论文主要用来非对齐图像的增强,这里只简要介绍一下文章的idea。这篇文章主要有三个创新点,分别如下:
1、对U-net进行修改,增加提取全局特征进行学习。
2、对WGAN进行改进,可以自动调整其权重系数。
3、在生成器中添加可以学习特定风格的individual BN层。
下面进行详细介绍。
这篇文章主要还是对unpair的图像进行增强,属于弱监督学习的范畴。所以采用的基本架构是2-way GAN生成器结构,如下图所示:
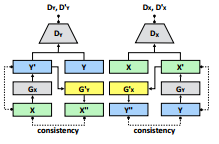
上图中,Gx和Gx’,Gy和Gy’是共享权重的,也就是说实际只有两个生成器,2-way GAN就是对这两个生成器和两个判别器进行训练,类似于cycleGAN和DualGAN,详情可以参考关于这方面的介绍。
生成器,带有提取全局特征的U-net
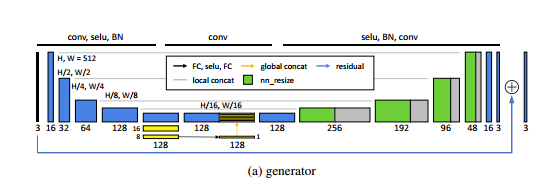
这里生成器是基于U-net,U-net在许多图像任务里都有很好的表现,但是在这里没有特别好的表现,论文认为主要是因为没有提取全局特征。视觉系统通常会根据全局的光线和场景条件做调整,全局特征通常可以反映高维的信息例如场景类别主题和全局的光线条件,这可以帮助像素做局部有的调整。因此,有必要在U-net上增加全局特征。
论文提出的U-net结构如下图所示,其提取全局特征的方式是这样的,首先前面几层都是使用5x5的卷积,stride=2,使用SELU激活和BN,然后变成32x32x128这个特征,接着特征进一步按照上述的操作转换成16x16x128,再到8x8x128的特征,这个特征通过一个全连接层转换成一个1x1x128的全局特征,然后被拷贝32x32份,变成32x32x128的全局特征,再和前面的那个32x32x128的局部特征concat在一起变成32x32x256的混合特征。最后,这个网络还采用了残差学习,也就是把输出加到了最后,网络学习的是输入和目标之间的残差部分。
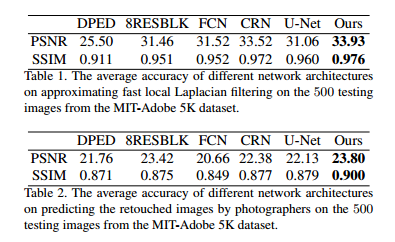
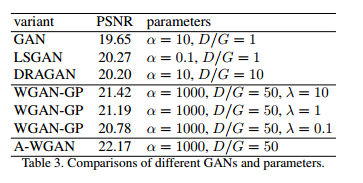
论文还对这个网络的性能做了对比实验,使用MIT-Adobe 5K数据集,在loss上使用MSE,和其他网络进行对比,结果如下,可以看出效果还是不错的。
对GAN的改进,可自适应调整权重系数
这个部分对应于论文里one-way GAN里的内容,这里论文对几种GAN做了对比实验,发现WGAN-GP的效果最好,但是WGAN-GP主要依赖于Lipschitz条件限制,这个限制是附带一个权重$\lambda$的,所以这个权重对于效果影响很大,如果权重过大,收敛会变得过慢。如果权重过小,Lipschitz条件又无法得到满足。这里gradient penalty被写成以下形式:
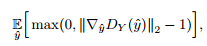
这里可以更加反映梯度应当小于或者等于1而只对大于1的部分做惩罚。而这里更重要的是采用了自适应的权重$\lambda$,先将梯度限制在[1.001,1.05]之间,如果梯度值在每次移动最终得到的结果大于1.05,那么说明目前的权重太小梯度惩罚不足,所以自动将权重加倍,反之如果梯度小于1.001,那么就将权重减为原来的一半。这样,就保证了稳定性。论文称自己的方法是A-WGAN。
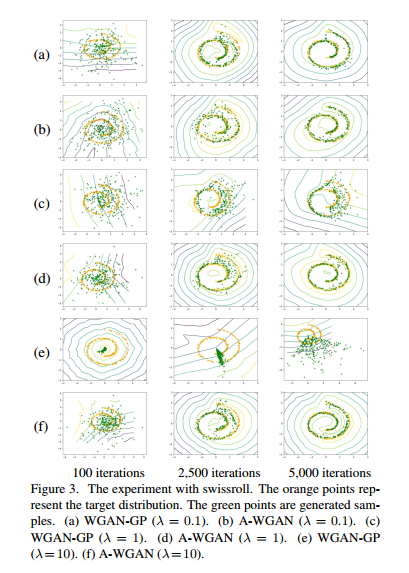
论文将自己的方法和其他方法做了一个对比,首先是稳定性的对比,如下图所示,ace是WGAN-GP,可以看出受到权重影响很大,bdf对应的A-WGAN受到的影响就小很多。
然后就是和其他的GAN对比了,可以看出效果也比较好,如下图所示:
individual BN层的使用
这个部分对应于论文里的two-way GAN的内容。使用上面的A-WGAN之后,two-way GAN也有了提升,不过相对于WGAN-GP来说,对比1-way GAN的提升更少,如下表所示:

在一般的two-way GAN的网络里,两个生成器要进行四次转换。例如,对于$G_x$和$G’_x$,它们其实是一个生成器,因为它们都是把X域转换到Y域,但是实际上它们转换的图像分布是不一样的,前者转换的是X,而后者转换的是X’。所以这个时候生成器完全一样是不合理的,这里给$G_x$和$G’_x$分别赋上各自的individual BN(iBN)层,去学习各自的输入的数据分布。上表也说明了加入iBN层之后有助于去学习各自的数据分布特征。
loss 设计与总结
这里的损失设计里,首先要求转换的图像y和x要在内容上相似,因此有:
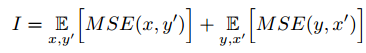
其次,还有two-GAN里常用的cycle consistency loss,就是让变换回的图像和原图像尽可能的像。
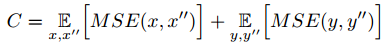
判别器和生成器的对抗损失分别定义如下:
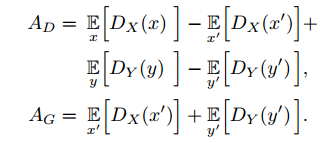
判别器里的惩罚项定义如下:
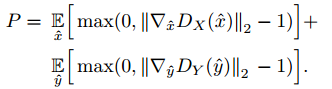
所以,判别器的总损失如下所示,其中$\lambda$可以自适应的改变(在A-WAGN中介绍的),如下所示:
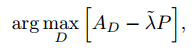
生成器的总损失总结如下,$\alpha$是对抗损失和identity/consistency loss之间的权重:
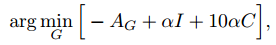
最后,将$G_x$作为生成器。从论文给出的效果图来看,还是比较理想的,如下图所示:

此外,作者提出的三个创新点在其他方面也有不错的表现:
