最近要参加4K+HDR比赛,因为之前没有做过视频方面的工作,所以想了解一些和视频超分相关的东东,网上这方面的资料很多,所以直接参考借鉴这些资料,以便快速了解。
RBPN(Recurrent Back-Projection Network for Video Super-Resolution)
论文认为流行的MISR或者VSR方法一般都是基于准确的运动估计和运动补偿(alignment),这个模式受到运动估计准确度的约束。RBPN希望改进这个模式。而在绝大部分基于CNN的方法中,都是对多张图片进行concat再送入网络,多张图片同步处理增加了网络的学习难度。RNN里同时处理细微和明显的变化是比较困难的,而DBPN可以比较有效的解决这个问题。该论文提出的encoder-decoder方法,用于通过反投影合并在SISR和MISR路径中提取的细节,RBPN中的这种机制扩大了RNN中的时间gap(t,t-1),使得时间跨度更大的帧也能被较好的利用。
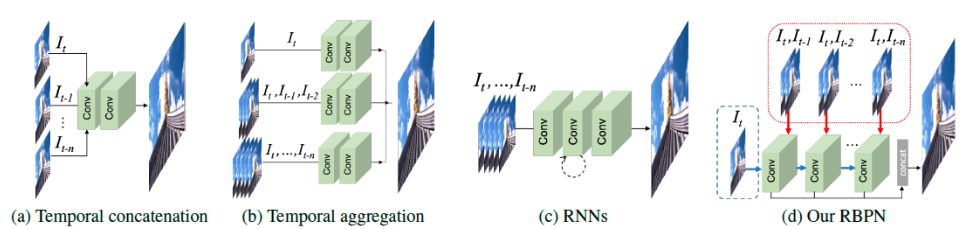
论文将目前的VSR方法分为下面这些结构,一目了然,不必赘述:
这里论文使用了encoder-decoder模型,但是一般的这种模型会导致后面的信息淹没前面的信息,这样解码的时候就没有足够的序列信息,这样解码的准确度就会下降,这里网络采取了如下结构:
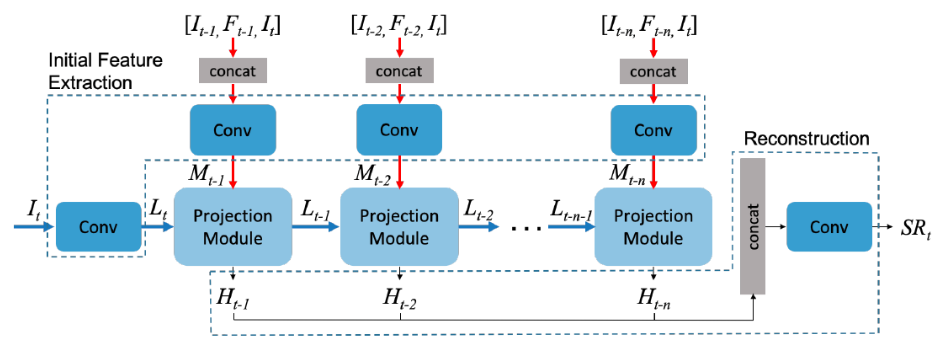
可以看出网络分成以下的部分,先是初始特征提取,MISR部分将$It$和$I{t-k}$帧以及光流$F{t-k}$concat在一起,进行卷积得到八通道的张量$M{t-k}$,SISR部分直接提取$I_t$帧特征$L_t$。
然后在多投影部分,这里如下图所示:
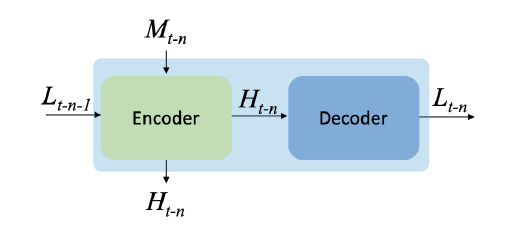
这里将上述两路分支输入进行上采样,获得的残差和SISR分支进行相加,得到输出$H{t-n}$。该输出再通过decoder进行下采样,获得$L{t-n}$,如下图所示:
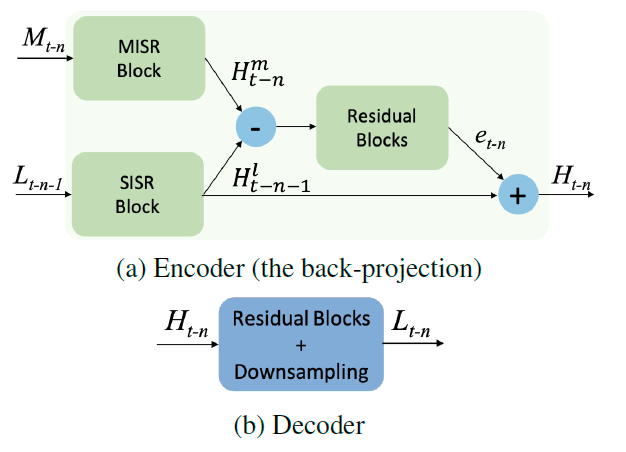
可以看出encoder和decoder就是相当于DBPN里的up和down操作,通过该单元的不断迭代更新低分特征,从而提高表现。
该部分参考:
https://blog.csdn.net/duoganniang1006/article/details/89848187
https://blog.csdn.net/nickkissbaby_/article/details/90518831
EDVR
这个工作就很有名了,copy网上的资料自己再写一下。
原来的视频重建可以看做是图像重建的简单扩展,这样相邻帧之间的信息就无法被充分利用。目前的方法一般通过特征提取,配准,融合和重建这四个步骤实现视频重建。对于对齐部分,目前主要有使用相邻帧和参考帧之间的光流进行对齐,以及使用deformable卷积进行对齐,这些现有方法没有考虑不同帧对于视频重建的增益是不同的,EDVR对此做出改进。
EDVR核心工作是分别设计金字塔级联变形对齐模块处理大的运动,其中使用形变卷积以由粗到细的方式在特征级别进行帧对齐。以及使用时空注意力融合机制强调后续重建的重要特征。整体流程图如下所示:
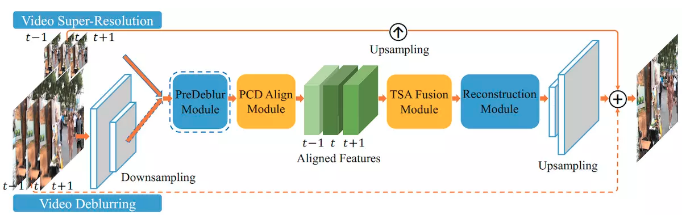
可以看出输入的若干帧先通过PCD模块进行对齐,然后通过TSA模块进行特征融合,最后进行特征重建进行上采样,结果与输入上采样进行相加,整体学习的是一个残差结构。
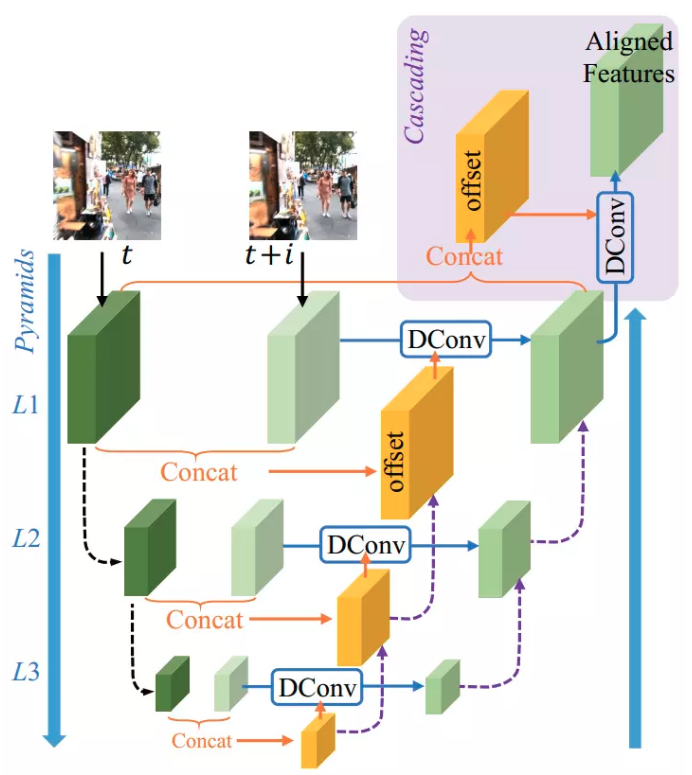
PCD模块如下所示,这里是一个coarse to fine的一个对齐模式,并在最后加上一个额外的对齐(最上面那个)提高对齐的鲁棒性,下采样采取的方式是stride为2的卷积。PCD模块是和其他模块在一起训练的,没有单独训练:
对于TSA模块,这里可以帮助融合多个对齐特征的信息,对每个帧的重要性进行赋值,引导图像进行重建的信息量。这些帧在时间上加权后进行融合,之后引入空间注意力为每一个通道每一个位置进行加权,更有效的利用跨通道和空间信息,如下所示(上面是时间注意力,下面是空间注意力):
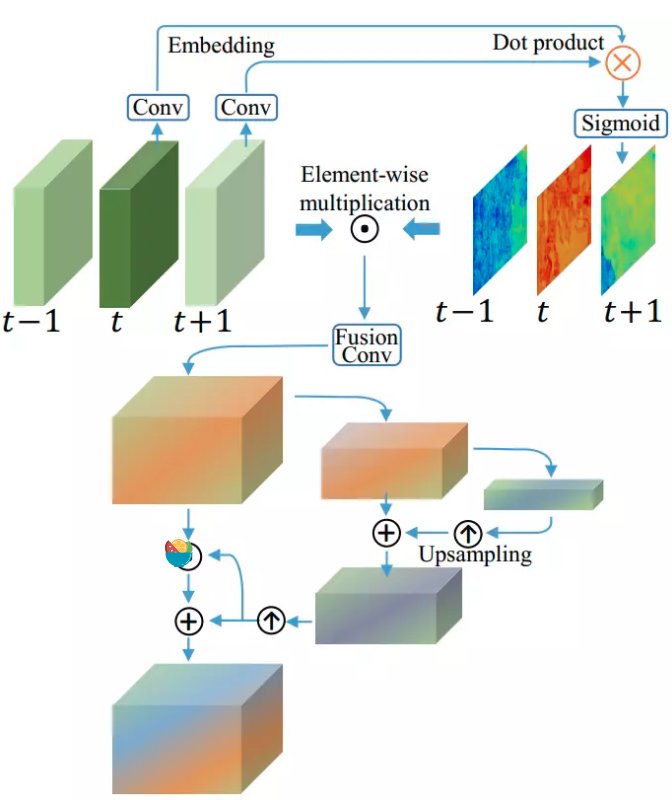
参考:https://www.jianshu.com/p/05abb917ae57
FRVSR
以往的视频超分将任务分解成大量独立的多帧超分辨任务,但是该类方法会导致每个输入帧被多次处理,增加了计算成本;每个输出帧独立的根据输入帧进行估计,限制了时间一致性。该论文提出一个端到端的可训练帧递归视频超分辨网络,将先前估计的HR作为后续迭代的输入。这种方法保证了每个输入帧只需处理一次,大大降低了计算成本,同时将先前估计的HR传播到后面的帧,有利于重建细节和保证时间一致性。整体结构如下所示:
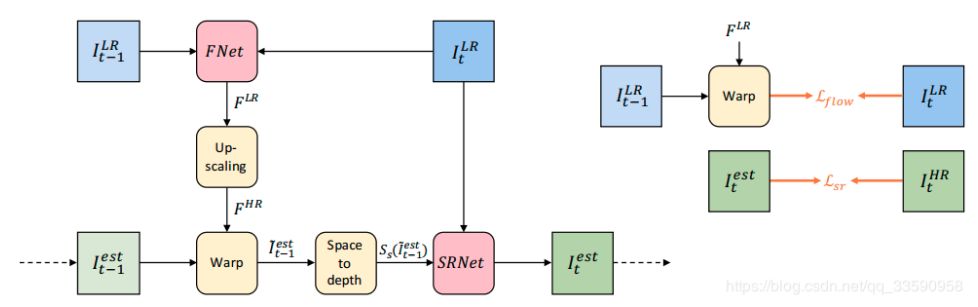
该框架由以下五步组成:
1.光流估计网络,通过$I{t-1}^{LR}$和$I{t}^{LR}$产生标准化的低分辨率光流图$F^{LR}$。光流网络如下所示:

2.对上一步获得的光流进行上采样,得到$F^{HR}$。
3.将上采样的光流和前一帧估计得到的HR进行warp,得到$I{t-1}^{est}$。
4.将上一步warp的结果通过pixel shuffle映射到LR空间中
5.将上一步得到的LR映射和$I^{est}{t}$连接起来,输入到SRNet中进行超分辨得到t时刻的超分辨结果$I_{t}^{est}$。如下所示:

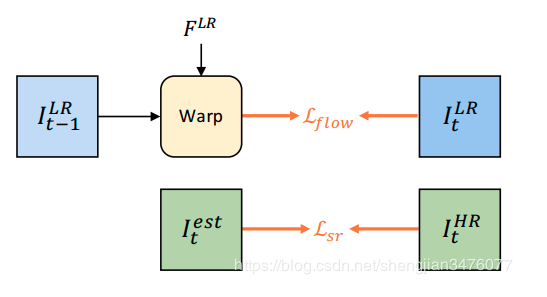
对于损失函数部分,这里包括输出当前帧和GT的L2 loss,和光流warp上一帧和当前帧的L2 loss用来估计光流,如下所示:
参考:
1.https://blog.csdn.net/shengjian3476077/article/details/89959035
2.https://blog.csdn.net/qq_33590958/article/details/89654853