简单总结一些特征融合的方法,方便以后使用
U-Net,U-Net++,HRNet
ExFuse: Enhancing Feature Fusion for Semantic Segmentation
语义特征和底层特征相结合,提升表现力,下图为一个通用模块解释,以及实际的方法和高级特征融合模块:
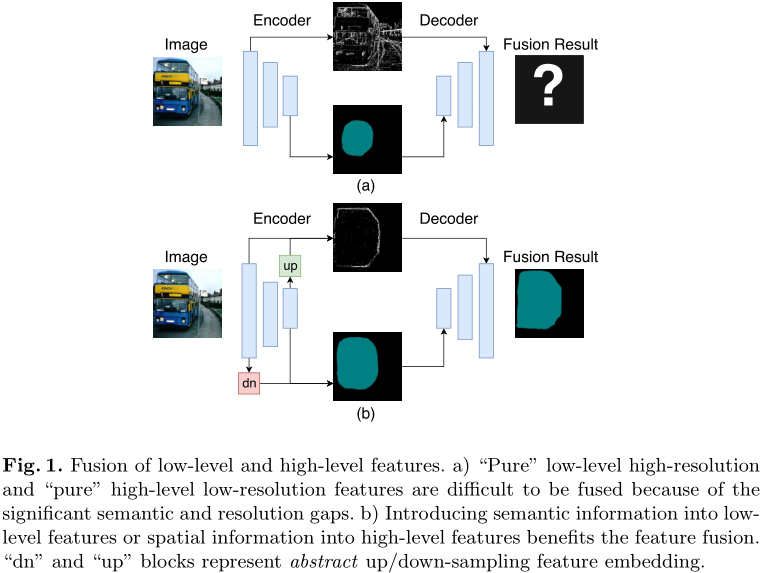
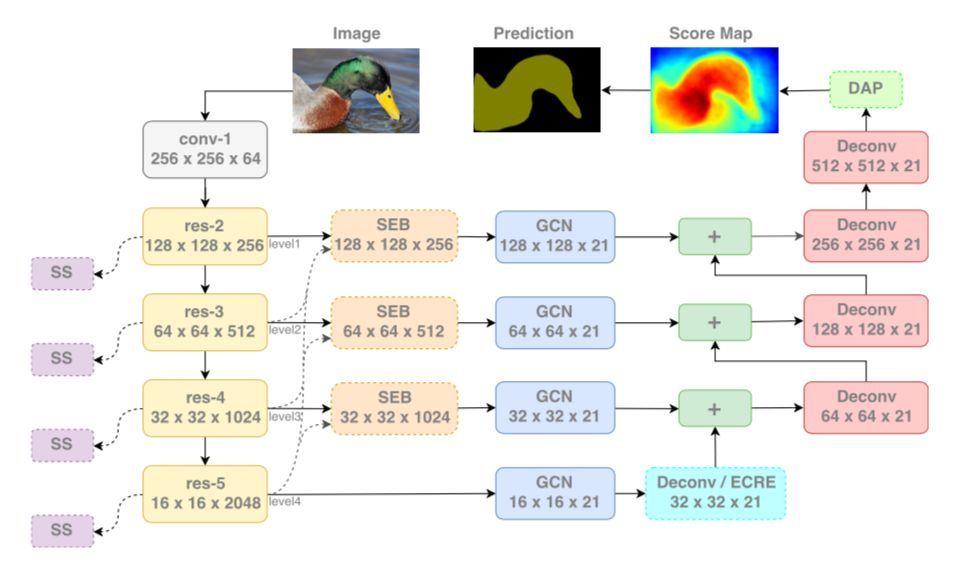
此外,论文还通过对编码器进行监督等方式进行提升,详细可以参考 https://zhuanlan.zhihu.com/p/40216927 的分析。
Libra R-CNN: Towards Balanced Learning for Object Detection
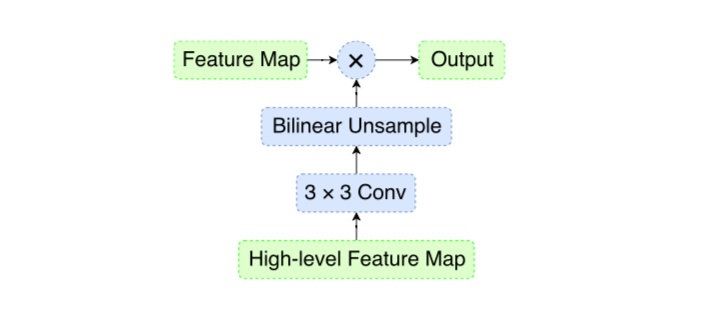
解决目标检测不平衡问题,这里特征融合用来解决特征不平衡的问题:
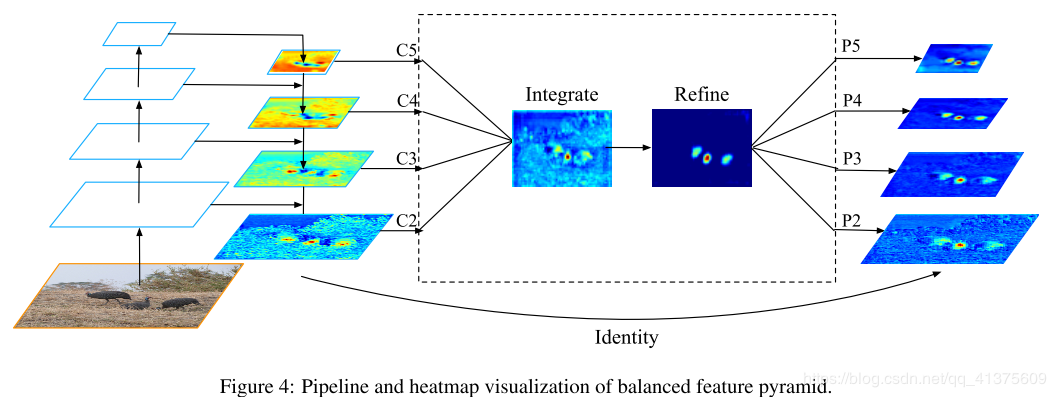
这里refine使用的是non local,此外论文里的unblance loss设计的也很有意思,详细可以参考 https://www.cnblogs.com/fourmi/p/10756556.html
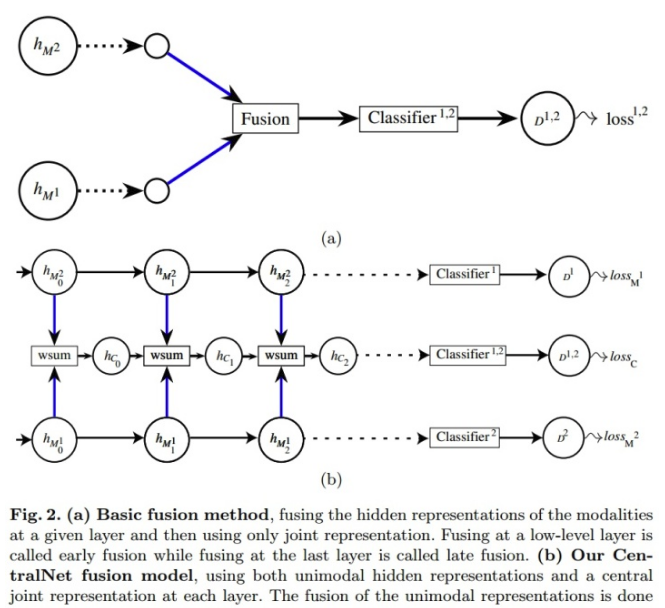
CentralNet: a Multilayer Approach for Multimodal Fusion
做多模态分类的,思路很简单,如下:
RefineNet和PSPNet
不说了,参考分割的论文
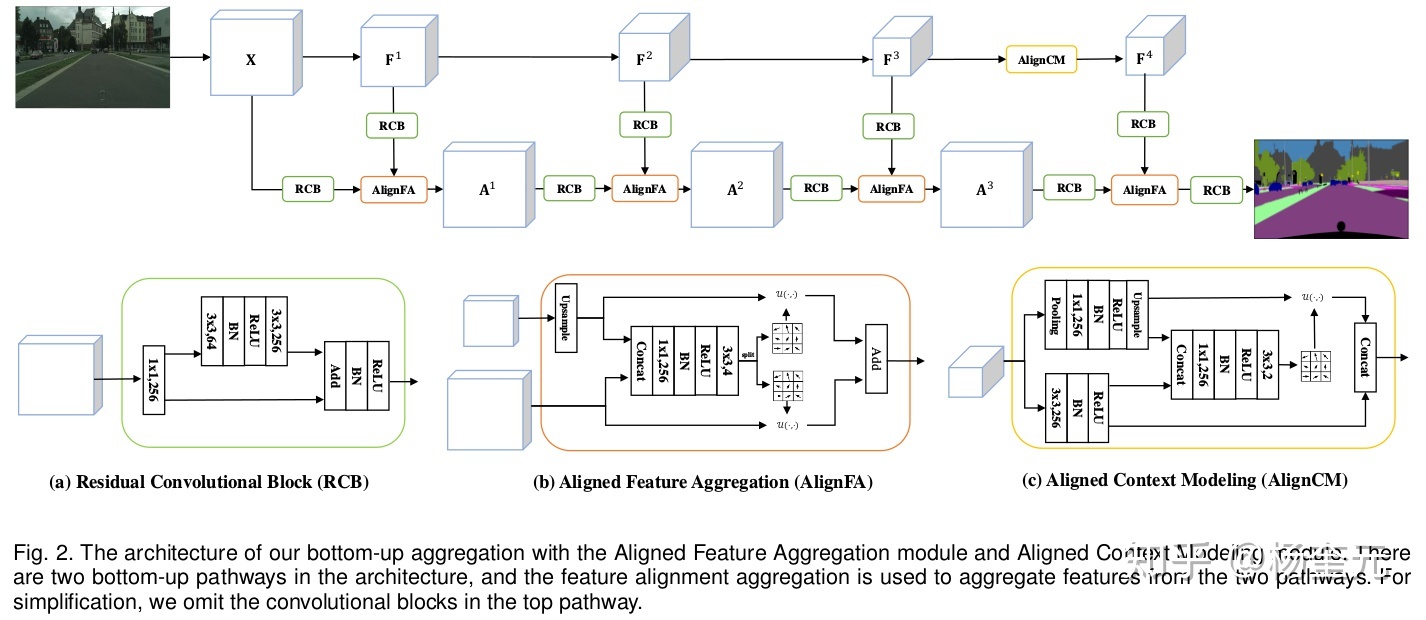
AlignSeg: Feature-Aligned Segmentation Networks
解决高低层特征不对齐问题(这个问题第一次看见),详情参考: https://zhuanlan.zhihu.com/p/110667995
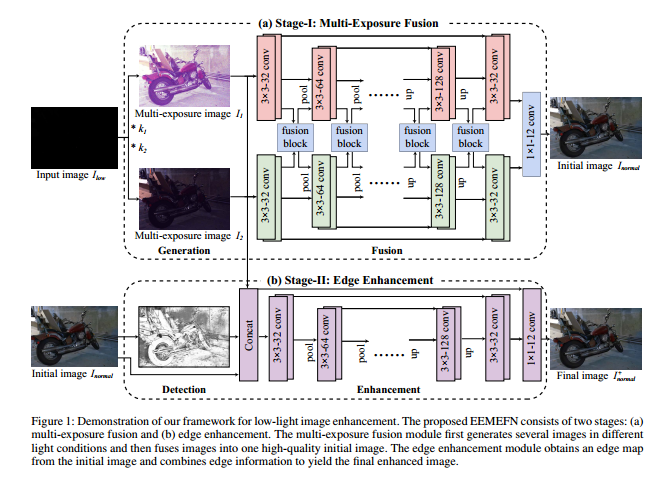
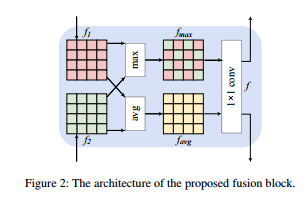
EEMEFN: Low-Light Image Enhancement via Edge-Enhanced Multi-Exposure Fusion Network
重点关注一下特征融合模块,论文详解参考: http://jiaqianlee.com/2020/01/25/LOW/
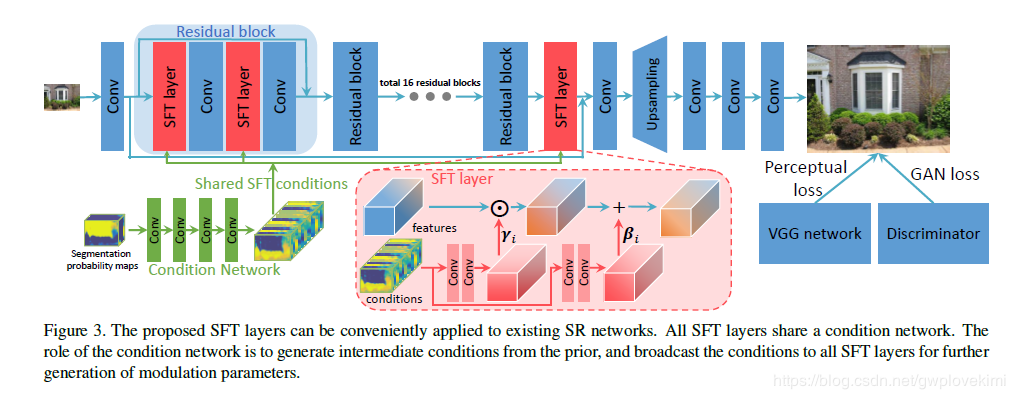
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform
语义分割图引导超分辨,实际上是特征转换,详情参考:https://blog.csdn.net/gwplovekimi/article/details/84697158
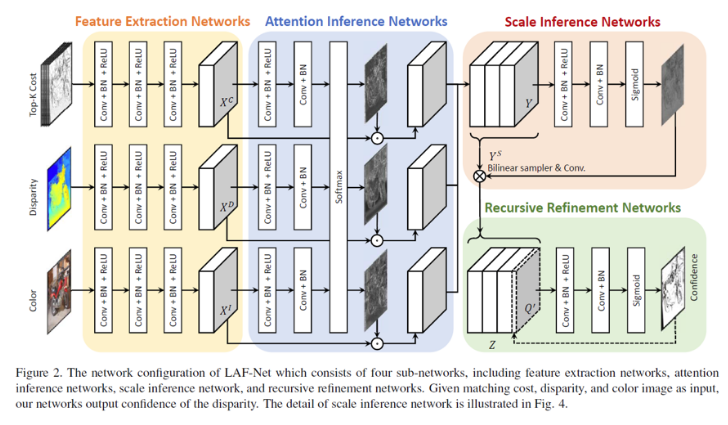
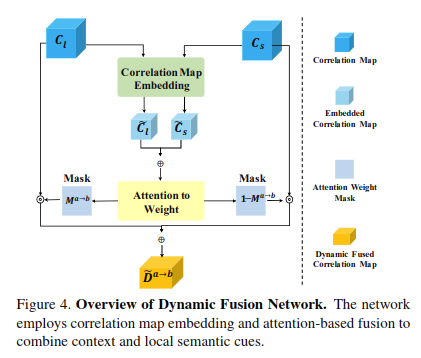
LAF-Net: Locally Adaptive Fusion Networks for Stereo Confidence Estimation
对不同特征不同重要程度进行编码,然后进行融合,如下图所示:
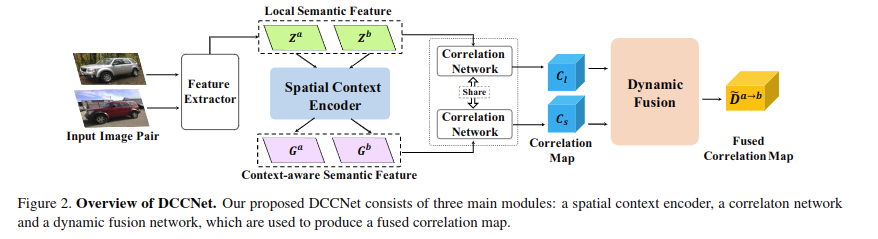
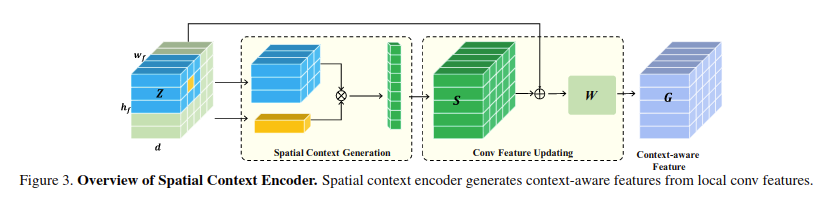
Dynamic Context Correspondence Network for Semantic Alignment
和上面出发点一样,对特征进行加权融合,如下所示:
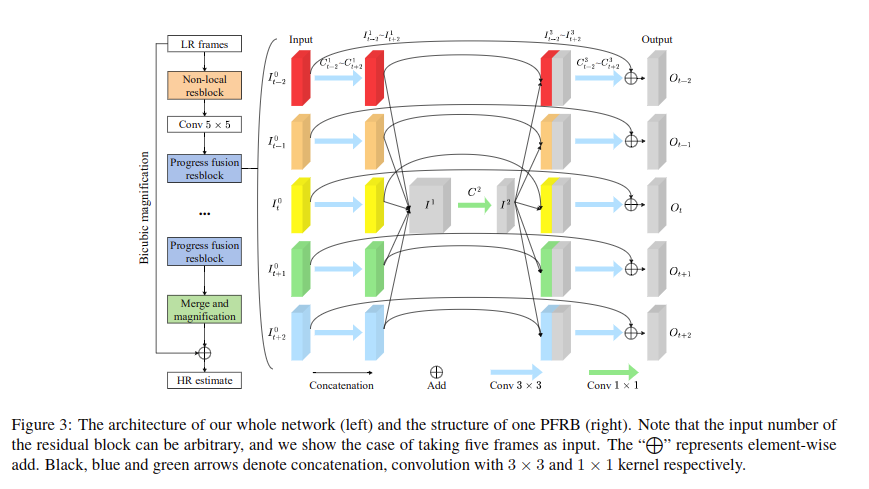
Progressive Fusion Video Super-Resolution Network via Exploiting Non-LocalSpatio-Temporal Correlations
空间时间信息融合,可以看做是一个类型的伪3D卷积
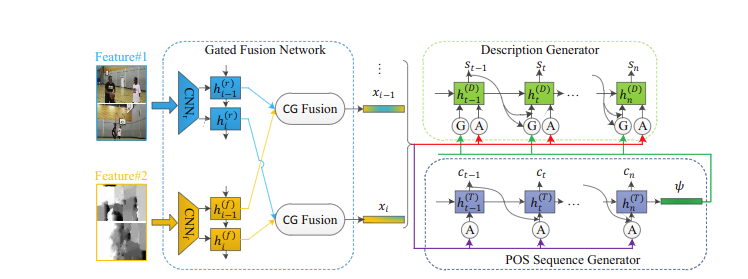
Controllable Video Captioning with POS Sequence GuidanceBased on Gated Fusion Network
RGB和D图像融合,如下图所示:
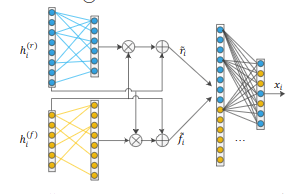
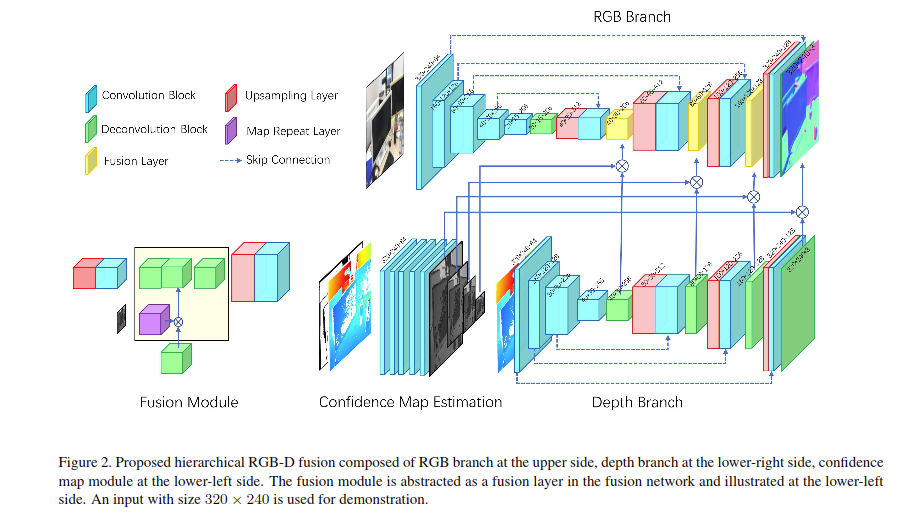
Deep Surface Normal Estimation with Hierarchical RGB-D Fusion
也是RGB和D图像融合,如下图所示,是一个coarse to fine的过程:
简单记录一下,有非常新的融合方式再更…