这是2017年CVPR做快速风格迁移的一篇论文,由于首先需要提高单幅图片的质量,对于这篇论文,本人还是先关注一下如何生成图像以及构建空间上的损失函数。这篇论文对于当前一般转换中使用的前馈网络里出现的问题,例如训练的照片分辨率比较固定,导致测试图片偏离训练图片尺寸太大或者太小时会出现局部失真的情况。事实上这种情况在前面本人跑DPED时就非常明显,使用快手图片生成的效果图局部失真很严重,所以个人感觉这篇论文还是比较有参考意义的。
和前面的很多论文类似,这篇论文也是将网络给分成了生成部分和损失部分,总体结构如下: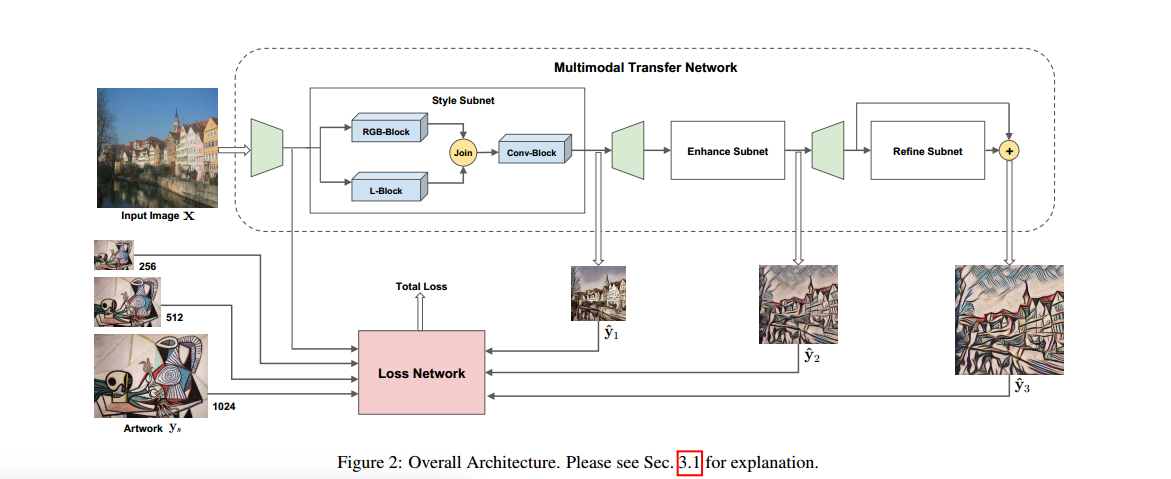
网络的整体思路差不多就是,将不同尺寸的输出图与不同尺寸的输入图进行比较得到各个层次的损失函数,再将这些损失函数组合起来进行训练。
下面分别对这损失函数和生成网络两部分作介绍。
损失网络
单一层的风格损失函数
这里定义损失和之前一些论文定义内容损失的方式一样,是在vgg19上进行相应的定义的,具体如下图所示: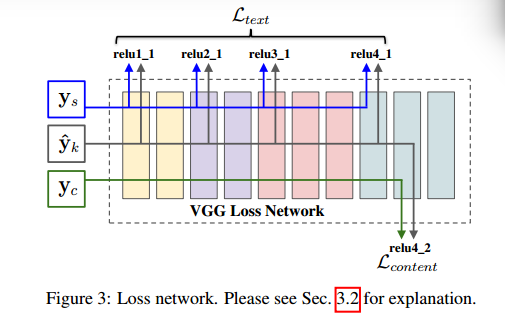
这里将每层的损失函数给分为了内容损失和纹理损失,定义的标准和之前许多论文一样,内容损失函数的定义如下:
所以,内容损失函数就是如图上各个层的误差平方和,如上式,其中$y_k$表示生成图,$y_c$表示内容目标(下同),$F_i^l$就是第l层的第i个特征图。
然后就是纹理损失或者风格损失的定义了,和前面的论文一样,这里也定义了Gram算子,这里不再赘述。纹理损失的定义如下:
这种Gram算子放弃了空间域的信息,保留了颜色和强度的统计信息。$y_s$表示风格化目标。
最后将这两者结合起来,构成了每层的损失:
这里$\alpha$ ,$\beta$分别是两部分的权重。
层级风格化损失函数
正如同第一个图所示,这里是将那张图中每一个网络输出部分的损失函数提取出来,组合成一个新的损失函数,如下所示:
这里k指的是第k个输出部分,总共有K个输出,在本文中,K=3。所以,对这个损失函数进行优化,优化的每一个网络部分的参数公式如下:
$\theta_k$就是所需要学习的网络每部分的最佳参数。
从这个公式也可以看出,k值越大,所需要学习的损失函数也就越少,即前层的损失有助于减少后层的损失,这样就减少了大量的内存以及运行时间。
生成网络的构建
单独的传输网络缺点是只能针对某一个尺寸的图像进行训练,这样导致捕捉图像的细节范围受到了限制。这里通过设计不同的子网层次,学习不同的层次特征。这种设计能够使图像学习不同层次的特征,同时后面的子网也能够增强和改进前面子网的效果,有利于增强模型的鲁棒性。
风格子网
风格子网先分别提取RGB特征和亮度特征,因为人对图片的亮度比较敏感。对于RGB特征网络,包括三个卷积层(9x9,3x3,3x3)和三个残差模块,亮度特征网络结构与之类似,但是卷积深度不一样,两者联合起来之后再通过一个卷积模块(内含三个残差块,其中两个用于上采样)输出,这里不使用反卷积是为了避免产生棋盘伪影。
增强子网和细化子网
样式子网对原图进行了大量的改变,使用增强子网可以用来进一步增加细节,细化子网则进行进一步的提取。增强子网的形式和样式子网相似,里面使用了上采样,对图像进行扩大,而细化子网只由三个卷积层,三个残差块,两个调整卷积层和一个输出层组成。正如前面所言,这样降低了学习的复杂性,加快了计算