这篇文章基本沿用了前面构建损失函数的一些思路,对于损失函数部分,这里的纹理损失函数仍然是基于Gram算子的,不同的是,这里的Gram算子只针对一张图作为目标,以其他图像的Gram算子和它的几何距离作为,定义如下:
这里的$x_0$就是那个选定的基准图像,x是生成的图像,下同。
对于内容损失,同前面论文,还是定义在CNN的某几层上面,定义如下:
论文发现使用多尺度架构可以在减少参数的情况下产生更小的纹理损失和训练的更快,网络架构如下所示: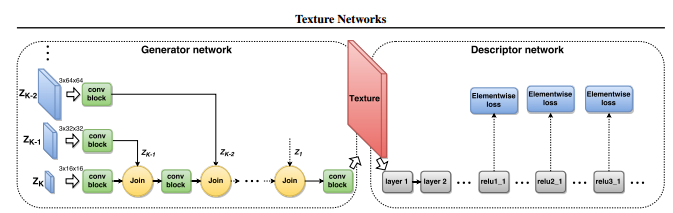
所以在具体的网络实现上,这里的输入是若干张原图像y和噪声图z,随着join数目的加深,图像的尺寸也不断增加,这里输入图像尺寸的增加主要通过上采样的方式得到。图中每个卷积块包括两个3x3的过滤器和一个1x1的过滤器。一般输入图像y的数目控制在3个。加入的噪声和图像数目总共为5或者6.
所以,学习目标为:
通过调整参数$\alpha$可以调整生成图像纹理特征和内容特征所占比例。lun