这是2018CVPR一篇做去噪的论文。其提出了一种CNN网络结构可以预测空间变化的核,以及利用每个位置的核去实现图像局部的配准和降噪。文章基于真实噪声生成模型合成训练数据,并利用退火损失函数去引导优化过程,避免陷入局部最优。文章的贡献在于:
1.将网上的数据,转换成具有RAW图像特性的数据。这使得训练模型可以推广到真实图像和环境中,解决了ground truth数据难以获取的问题。
2.提出一个网络,其性能在合成数据和真实数据上都优于现有水平。其可以对每个位置生成一个3D去噪核,从而生成去噪图像。
3.提出一个针对该网络的训练流程,使得网络可以利用多张图像信息预测滤波核,即使它们之间存在小的不对齐。
4.证明了在训练和测试时,将输入图像的噪声水平作为网络的输入,得到的网络将会对更宽的的噪声水平范围具有鲁棒性。
论文的目标是产生一张干净的图像,从N张从移动相机里获得的噪声图像里。所有图像处理的过程都是在raw空间里进行,从而避免信息的缺失。
Characteristics of raw sensor data
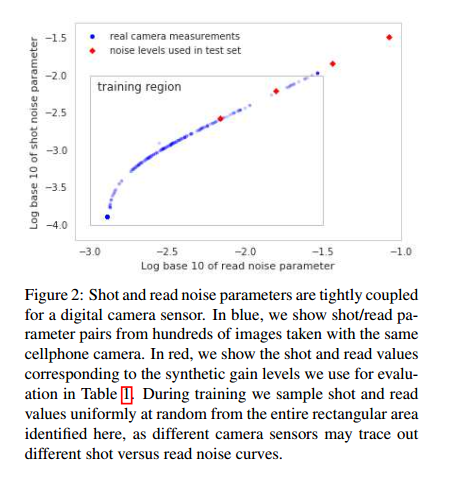
相机噪声主要有两种,包括short noise,其服从一个泊松分布,方差为信号水平;以及read noise,其服从高斯分布,由多种传感器读入造成。这些效应可以通过一个信号非独立的高斯分布进行建模,如下所示:
其中,$x_p$是位于像素p位置的真实亮度y_p的一个噪声测量。噪声参数$\sigma_r$和$\sigma_s$对于每张图片是固定的,其只随ISO变化而改变。此外,还需要将像素减去一个black level,从而使得black pixel确实是0。
Synthetic training data
为了生成N张图像,这里适当的引入偏移和噪声合成训练数据,模拟真实图像序列的特性。首先利用一张图像,使其发生微小的位移$\triangle_i$,位移服从2D均匀整数分布。然后对这些裁剪的图像在每个维度上使用box filter做四倍的下采样,下采样后图像和参考图像之间最多只存在两个像素的偏移。 为了模拟由于存在大位移而配准失败的情况,对于每一图像序列随机挑选n~Possion($\lambda$)帧图像,下采样后做最大16个像素的偏移。
为了生成合成噪声,首先进行gamma逆变换,使其转换到近似线性颜色空间。然后线性放缩数据,缩放比例从[0.1,1]区间中随机采样,避免数据出现高亮截止区域。最后通过从真实数据中观察到的噪声参数关系中,采样获得$\sigma_s$和$\sigma_r$,利用上面的噪声模型对图像序列添加噪声。
Model
这里的网络使用的是核预测网络,其同时配准、平均和去噪一副图像,生成参考帧的干净版本。这里的KPN网络使用了一个编解码结构,其有$K^2N$个输出通道,可以被变形为N个KxK大小的线性滤波核。则输出Y的像素表示为:
其中,V是指图像X像素p的KxK的邻域,$f_i^p$是其对应的核。Y是使用空间里不同的核对每张图像预测之后求均值的结果。除了RAW数据作为输入外,网络还使用逐像素估计的信号标准偏差作为输入。对噪声的逐像素估计为:
其中,$x_p$是是图像序列中第一张图像像素p的亮度。假设$\sigma_s$和$\sigma_r$已知。
Loss
这里的loss包括两个,一个是基本损失函数,基于sRGB变换函数,另外一项是退火项。直接优化损失函数会收敛于局部最小值(只有参考帧核非零,其余核都变为0)。为了使得网络能充分利用其它帧的信息,文章使用退火策略,在初始时刻,使得输出的核能对图像序列中的每一帧分别配准和降噪,然后再利用各帧之间的信息做加权叠加。