1月22日 BiSeNet:实现实时语义分割
来源: https://zhuanlan.zhihu.com/p/41475332
U型结构的缺点:1)由于高分辨率特征图上额外计算量的引入,完整的 U 形结构拖慢了模型的速度。2)更重要的是,如图 1(b) 所示,绝大多数由于裁剪输入或者减少网络通道而丢失的空间信息无法通过引入浅层而轻易复原。换言之,U 形结构顶多是一个备选方法,而不是最终的解决方案。

基于上述观察,本文提出了双向分割网络(Bilateral Segmentation Network/BiseNet),它包含两个部分:Spatial Path (SP) 和 Context Path (CP)。顾名思义,这两个组件分别用来解决空间信息缺失和感受野缩小的问题,其设计理念也非常清晰。
对于 Spatial Path,本文只叠加三个卷积层以获得 1/8 特征图,其保留着丰富的空间细节。对于 Context Path,本文在 Xception 尾部附加一个全局平均池化层,其中感受野是 backbone 网络的最大值。图 1(c) 展示了这两个组件的结构。在追求更快、更好模型的过程中,本文也研究了两个组件的融合,以及最后预测的优化,并分别提出特征融合模块(Feature Fusion Module/FFM)和注意力优化模块(Attention Refinement Module/ARM)。在 Cityscapes,CamVid 和 COCO-Stuff 数据集上的实验表明,这两个模块进一步从整体上提升了语义分割的精度。
Spatial Path
本文提出 Spatial Path 以保留原输入图像的空间尺度,并编码丰富的空间信息。Spatial Path 包含三层,每层包含一个步幅(stride)为 2 的卷积,随后是批归一化和 ReLU。因此,该路网络提取相当于原图像 1/8 的输出特征图。由于它利用了较大尺度的特征图,所以可以编码比较丰富的空间信息。图 2(a) 给出了这一结构的细节。

Context Path
在本工作中,轻量级模型,比如 Xception,可以快速下采样特征图以获得大感受野,编码高层语义语境信息。接着,本文在轻量级模型末端添加一个全局平均池化,通过全局语境信息提供一个最大感受野。在轻量级模型中,本文借助 U 形结构融合最后两个阶段的特征,但这不是一个完整的 U 形结构。图 2(c) 全面展示了 Context Path。
注意力优化模块(ARM):在 Context Path 中,本文提出一个独特的注意力优化模块,以优化每一阶段的特征。如图 2(b) 所示,ARM 借助全局平均池化捕获全局语境并计算注意力向量以指导特征学习。这一设计可以优化 Context Path 中每一阶段的输出特征,无需任何上采样操作即可轻易整合全局语境信息,因此,其计算成本几乎可忽略。
网络架构
在 Spatial Path 和 Context Path 的基础上,本文提出 BiSeNet,以实现实时语义分割,如图 2(a) 所示。本文把预训练的 Xception 作为 Context Path 的 backbone,把带有步幅的三个卷积层作为 Spatial Path;接着本文融合这两个组件的输出特征以做出最后预测,它可以同时实现实时性能与高精度。
首先,本文聚焦于实际的计算方面。尽管 Spatial Path 有大感受野,但只有三个卷积层。因此,它并非计算密集的。对于 Context Path,本文借助一个轻量级模型快速下采样。进而,这两个组件并行计算,极大地提升了效率。第二,本文还讨论了网络的精度方面。Spatial Path 编码丰富的空间信息,Context Path 提供大感受野,两者相辅相成,从而实现更高性能。
特征融合模块:在特征表示的层面上,两路网络的特征并不相同。因此不能简单地加权这些特征。由 Spatial Path 捕获的空间信息编码了绝大多数的丰富细节信息。而 Context Path 的输出特征主要编码语境信息。换言之,Spatial Path 的输出特征是低层级的,Context Path 的输出特征是高层级的。因此,本文提出一个独特的特征融合模块以融合这些特征。在特征的不同层级给定的情况下,本文首先连接 Spatial Path 和 Context Path 的输出特征;接着,通过批归一化平衡特征的尺度。下一步,像 SENet 一样,把相连接的特征池化为一个特征向量,并计算一个权重向量。这一权重向量可以重新加权特征,起到特征选择和结合的作用。图 2(c) 展示了这一设计的细节。
1月23日 如何理解网络中通过add的方式融合特征
来源: https://www.zhihu.com/question/306213462
对于两路输入来说,如果是通道数相同且后面带卷积的话,add等价于concat之后对应通道共享同一个卷积核。下面具体用式子解释一下。由于每个输出通道的卷积核是独立的,我们可以只看单个通道的输出。假设两路输入的通道分别为X1, X2, …, Xc和Y1, Y2, …, Yc。那么concat的单个输出通道为(*表示卷积)
而add的单个通道输出为:
因此add相当于加了一种prior,当两路输入可以具有“对应通道的特征图语义类似”,性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。
总之,当feature的性质相近时,或者保持mapping的identity性质,使梯度回传得更加容易,也可以使用add的方式。
1月24日 PAYING MORE ATTENTION TO ATTENTION: 通过注意力迁移提高CNN性能
来源:https://zhuanlan.zhihu.com/p/55643612
本文展示了通过给CNN定义合适的注意力,我们可以通过强迫student CNN模仿teacher CNN的注意力图极大的提升student CNN的性能。最后,我们提出了几个新颖的注意力迁移方法,在多个数据集和卷积网络上都有稳定的提升。
首先需要正确定义一个网络的注意力。我们考虑注意力作为一个空间图,它把网络为了输出决策(例如图像分类)而对输入中最感兴趣的区域进行编码,这个图可以定义为能够捕获低层,中层,高层的表示信息的各个网络层。具体而言,在本文中,我们定义了两种空间注意力图:基于激活(activation-based)的空间图和基于梯度(gradient-based)的空间图。我们探索了这些注意力图在不同数据集和网络结构上的变化,展示了其中蕴含的信息可以极大地帮助提升卷积网络的性能。最后,我们提出了一个从teacher到student网络迁移注意力的新方法(图1)。
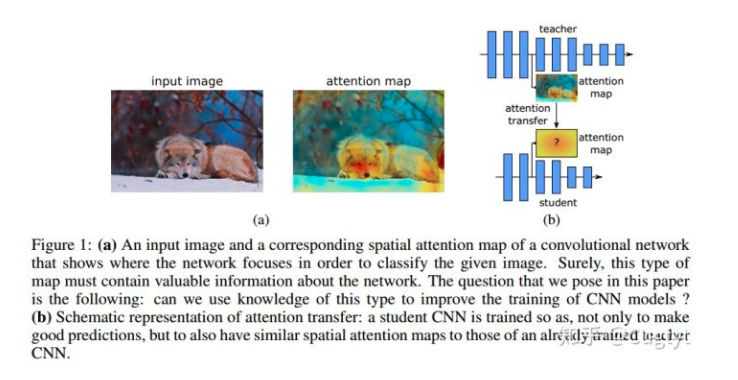
我们工作的贡献在于:
提出了让注意力作为从一个网络到另一个网络的知识迁移机制
提出了同时使用基于激活和基于梯度的空间特征图
实验证明了我们的方法在多个不同的数据集和深度网络中有极大的提升,包括残差网络和非残差网络
展示了基于激活的注意力迁移比激活迁移有更好的提升,可以和知识蒸馏结合在一起
考虑一个CNN层和对应的激活张量A∈RC×H×W,c个通道,每个维度是H×W。基于激活的映射函数F把这个3维张量作为输入,输出一个2维空间特征图。为了定义这个空间注意力映射函数,我们的一个潜在假设是,隐层神经元激活(网络在预测时的结果)的绝对值可以用于指示这个神经元的重要性,这样我们可以计算通道维度的统计量
具体而言,我们考虑如下的空间注意力图:
绝对值求和:$ F { \operatorname { sum } } ( A ) = \sum { i = 1 } ^ { C } \left| A { i } \right|$
绝对值指数求和,指数大于1: $F { \mathrm { sum } } ^ { p } ( A ) = \sum { i = 1 } ^ { C } \left| A { i } \right| ^ { p }$
绝对值指数求最大值: $F { \max } ^ { p } ( A ) = \max { i = 1 , C } \left| A _ { i } \right| ^ { p }$
其中, Ai=A(i,:,:)(MATLAB 记号),最大值,指数和绝对值都是元素级别的操作。
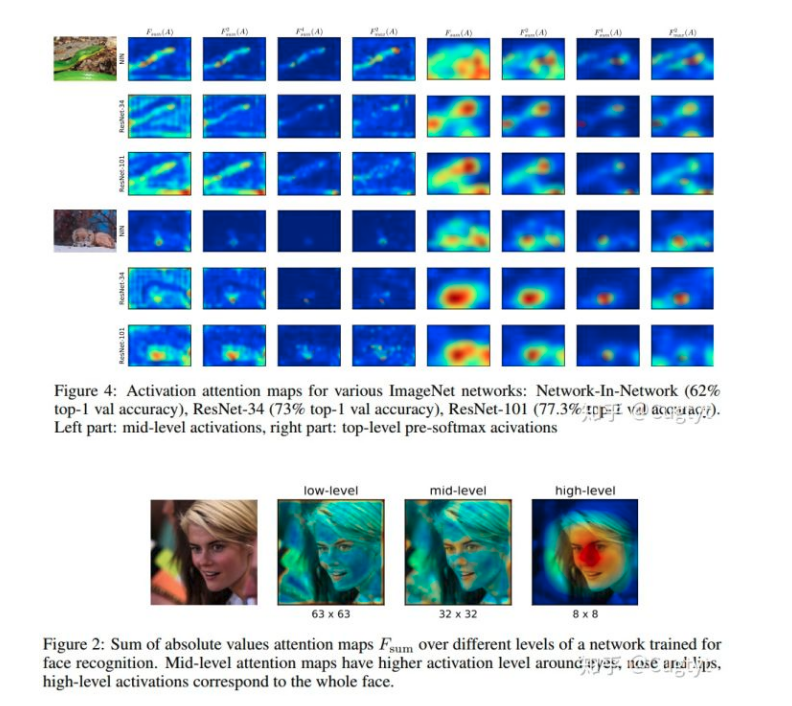
我们可视化了在多个数据集上多种网络,包括ImageNet分类和定位,COCO目标检测,人脸识别等。我们不带顶层线性全连接层,例如Network-InNetwork, ResNet and Inception,他们都有流线型的卷积结构。我们也在相同结构,宽度和深度的网络上,但是在不同的框架上训练得到了截然不同的性能。我们发现隐层激活的统计信息不仅有空间相关性,而且这些相关性与准确率有很强的关系,更强大的网络有更尖锐的注意力(图4)。网络中不同的层有不同的注意力图,关注与不同的地方。前面的层对于低层次梯度点激活程度很高,中间层对于最有判别性的区域激活很高,顶层会反映出整体的目标,例如图2。
我们可视化了在多个数据集上多种网络,包括ImageNet分类和定位,COCO目标检测,人脸识别等。我们不带顶层线性全连接层,例如Network-InNetwork, ResNet and Inception,他们都有流线型的卷积结构。我们也在相同结构,宽度和深度的网络上,但是在不同的框架上训练得到了截然不同的性能。我们发现隐层激活的统计信息不仅有空间相关性,而且这些相关性与准确率有很强的关系,更强大的网络有更尖锐的注意力(图4)。网络中不同的层有不同的注意力图,关注与不同的地方。前面的层对于低层次梯度点激活程度很高,中间层对于最有判别性的区域激活很高,顶层会反映出整体的目标,例如图2。
对于上面说的不同的注意力映射函数,有一些属性上的微小差别:
与Fsum(A)相比,空间图Fpsum(A)对有更高激活的空间位置有更多的权重,也就是对最优判别性的部分赋予更多的权重。
在相同空间位置的所有激活中,Fpmax(A)只考虑其中一个来赋予权重,而Fpsum(A)更倾向于多个神经元都激活的区域。
为了进一步说明区别,我们可视化了3个性能截然不同的网络:Network-In-Network (62% top-1 val accuracy), ResNet-34 (73% top-1 val accuracy) and ResNet-101 (77.3% top-1 val accuracy),每个网络我们取了最后一个下采样前的激活图,在图4中左边是中间层,右边是顶层均值池化前的激活图。顶层的有些模糊了,因为他的原始空间分辨率只有7*7。很明显最具有判别性的区域有更高的激活级别。
在注意力迁移中,给定teacher网络的空间激活图,我们的目标是训练一个student网络能不只是做正确的预测,同时也要有和teacher相似的激活图。通常我们可以加一个迁移损失,例如对于ResNet而言,可以考虑下面两种情况,这取决于teacher和student的深度:
相同的深度:可以在每个残差块后做注意力迁移
不同的深度:对每个组的激活图做注意力迁移
1月25日 [ICCV2017][IJCAI2018]当低级视觉任务遇上高级视觉任务
Deep Generative Adversarial Compression Artifact Removal[1],ICCV2017
主要贡献如下:
- 设计了简单有效的生成器网络,并对比使用 MSE,SSIM,判别器对抗学习 三种不同的 Loss,对图像decompression去压缩任务的客观/主观质量的影响。
- 基于压缩算法一般先将图像分成patches再进行DCT的思想,判别器也是基于图像sub-patch level 来操作,可更好消除 mosquito noise。
- 探索了compression artifacts对深度学习目标检测器的影响,及decompression去压缩对检测器性能的提升。
生成器网络架构如下图:
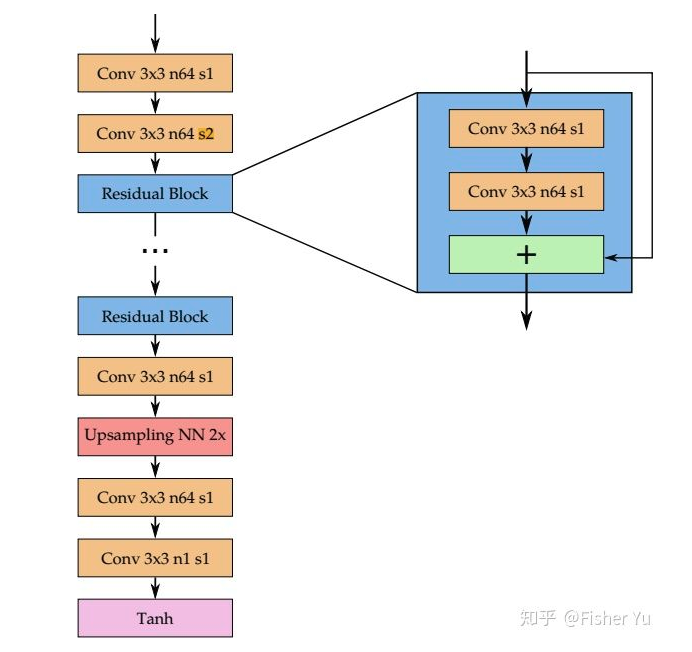
简单地堆残差block,只用了一个下采样及上采样来减少计算量,全卷积网络(即可在小Patch(128128)进行训练,然后应用到更大的图片里;因为压缩损失一般是基于小block及macroblock)。
对于损失函数的设计,文中对比了以下三种:
1.MSE loss ,即对应 客观质量评价指标PSNR,故理论上使用MSE loss,监督出来图像的PSNR值会高。
2.SSIM loss, 即对应 客观质量评价指标SSIM,故理论上使用SSIM loss,监督出来图像的SSIM值会高。
3.基于生成对抗的 loss,保证分布相似及主观质量较好。
其中包括了判别器sub-patch loss l{d} , perceptual loss l{p} 及 对抗 loss l_{adv} 。
对于判别器,其输入是生成器输出的(128128)patch分成1616的sub-patches,这是针对压缩算法的特点设计的。
*When Image Denoising Meets High-Level Vision Tasks[2],IJCAI2018
跟上面文章的思路不同,本文探索的是:
1.在低级视觉任务与高级视觉任务进行联合训练时候,两个任务是如何相互促进的?
2.联训后的低级视觉任务,迁移到其他高级视觉任务,泛化能力如何?是否也能提升cross-task的性能呢?
文中用的denoising网络比较简单,类似VDSR+UNet的形式,encoder与decoder中的连接也是使用concat形式。
OK,来接着谈谈与高级视觉任务联训,如果是单任务(仅仅图像识别或者语义分割)的话,应该是低级任务网络和高级任务网络里参数都进行finetune,且使用权值叠加的低级高级Loss,效果最好。但文中为了验证联训出来的低级网络的泛化能力,就统一把高级任务网络中的参数fixed住,即对比以下几种情况:
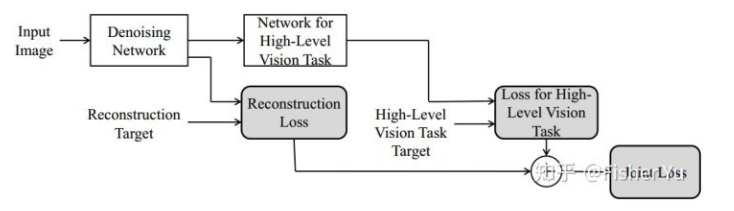
- Baseline: 带噪声的图像直接给预训练好的VGG进行分类。
- Separate+VGG:Denosing网络单独训练,生成去噪完图片丢给预训练好的VGG进行分类。
- Joint Training: Denosing网络使用 Joint loss 进行训练,VGG加载预训练的模型并fixed参数进行分类。
- Joint Training (Cross-Task): Denoising网络与语义分割任务进行 Joint loss 训练(语义分割里使用的DeepLab也是预训练好,参数fixed的),后接预训练好的VGG进行分类测试。
定量的结果如上表所示,Joint training性能比Separate training效果要好,且对不同的高级视觉任务的泛化能力保持得很好。
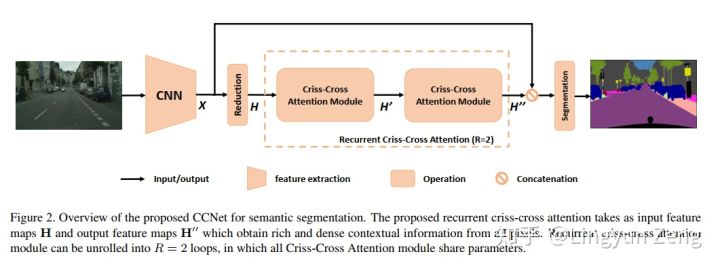
1月27日 CCNet: Criss-Cross Attention for Semantic Segmentation
来源:https://zhuanlan.zhihu.com/p/51393573
(一种为语义分割设计的十字型attention….哈,论一个好标题的作用:它可能是设计了一种十字型attention,用在语义分割里效果杠杠的)。下图蓝色点为待处理像素点 x{i} ,处理后得到结果为红色点 y{i} :
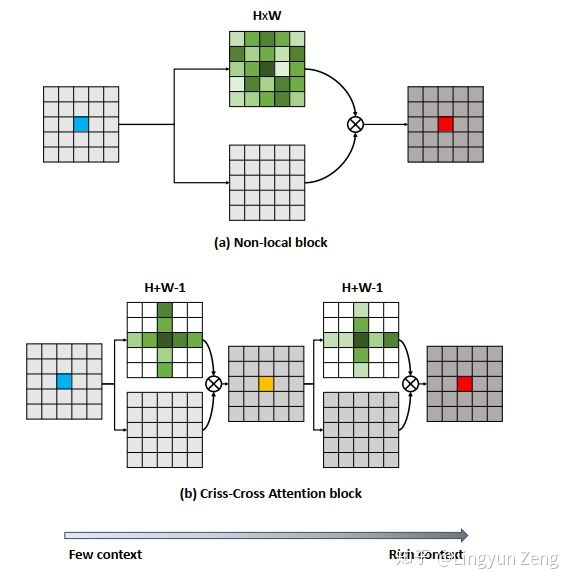
a)是Non-local,含蓝色中心的feature map是输入,分为上下两个分支处理:
深绿色分支代表已经完成Non-local操作,得到了 f(x{i},x{j}) (绿色的深浅则代表了当前位置与蓝色中心点的相关性大小);
下面灰色分支代表进行了 g(x{j}) 操作。将两个结果相乘,得到 y_i (含红色中心的feature map).
b)即为CCNet的改进,可以看到,深绿色 f 部分是十字型结构,意即只计算当前 x{i} 周围十字型区域像素 x{j} 与它的相关性。当然,我们需要知道是 所有像素 与 x{i} 的相关性,于是作者将这个过程进行堆叠,并且通过实验发现,只需堆叠两次即可覆盖所有点,并超越non-local的效果。
为什么堆叠两次即可?
我们先看看信息是如何通过十字型结构传递的:
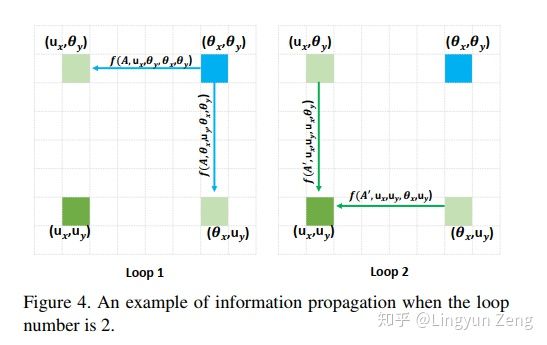
上图展示了蓝色像素点的信息传达到左下角点的过程:
第一次loop1,我们在计算左下角点的f时,只能包含左上角点和右下角点的信息,此时并没有左下角点与蓝色点的相关信息。
但在计算左上(or右下)点时,是计算了蓝色点与它们的相关性信息的。
第二次loop2,当我们再次计算左下角点的 f 时,再次包含左上&右下点的信息,此时的左上&右下已经不是当初那个它们了2333,它们已经有了蓝色点 的信息,此时便可以间接地将蓝色点信息传递给左下点。
同理,其他不在左下点十字型位置的像素点,都可以通过这种方式在第二次loop的时候就将信息传递给左下点。于是实现两次loop便“遍历”了所有点。
事实上,我们可以发现蓝色点信息是传递了两遍给左下点的(左上传递了一次,右下传递了一次),虽然是间接传递没有直接计算得到的结果强度大,但这种对于信息的两次加强也很有可能是最终效果 略胜于 Non-local的原因之一。
于是乎,原本需要计算 (HW)^{2} 次,现在变为了 (HW)(H+W-1) (一共 HW 个像素点,每个点只”观照”其十字型区域 (H+W-1) 面积的像素)。计算效率大大提升!
以下是CCNet的网络结构: